


GATE 2021 Computer Science and Information Technology (CS, Set-2) Question Paper for February 13 afternoon session was rated moderate to difficult. GATE 2021 Computer Science & Information Technology question paper had a combination of MSQs, MCQs, and NAT questions. As per the feedback given by test takers, the questions of 1 and 2 marks were not in sequence. The maximum number of questions were asked from Database, Discrete Mathematics, and TOC. Check GATE CS Syllabus
As compared to last year’s GATE CS question paper, many students found GATE 2021 question paper a bit difficult. GATE 2023 aspirants can download GATE 2021 CS Question Paper with Answer Key PDFs given below.
GATE 2021 Computer Science and Information Technology (CS, Set-2) Question Paper with Solutions
| GATE 2021 Computer Science and Information Technology (CS, Set-2) Question Paper | Check Solutions |

Gauri said that she can play the keyboard \hspace{2cm} her sister.
View Solution
Step 1: Understanding the sentence structure.
The sentence compares Gauri’s ability to play the keyboard with her sister’s ability. Such a comparison requires a grammatically correct comparative phrase.
Step 2: Use of correct comparative expression.
The phrase as well as is used to show equality or similarity in ability or performance between two people. It correctly fits the context of the sentence.
Step 3: Eliminating incorrect options.
The expressions as better as, as nicest as, and as worse as are grammatically incorrect because comparative and superlative adjectives cannot be used in this structure.
Step 4: Conclusion.
Therefore, the correct and grammatically sound option is as well as.
Final Answer: (A) as well as Quick Tip: Use \textbf{as well as} to compare equal abilities. Avoid mixing comparative or superlative forms with the “as … as” structure.
A transparent square sheet shown above is folded along the dotted line. The folded sheet will look like \hspace{2cm}.


View Solution
Step 1: Identify the line of folding.
The dotted vertical line represents the axis of folding. Since the sheet is transparent, all markings on one side of the fold will appear mirrored on the other side after folding.
Step 2: Analyze the curve and markings.
The curved shape and the small angular markings on the right side of the dotted line will reflect symmetrically to the left side when folded. The relative orientation of these markings must be reversed horizontally.
Step 3: Compare with given options.
Option (B) correctly shows:
the mirrored curvature,
correct alignment of the angular markings,
proper overlap produced by transparent folding.
Options (A), (C), and (D) either misplace the mirrored curve or incorrectly orient the internal markings.
Step 4: Conclusion.
Therefore, the folded transparent sheet will look like option (B).
Quick Tip: In transparent folding problems, always reflect every detail across the fold line and check orientation carefully.
If \(\theta\) is the angle, in degrees, between the longest diagonal of the cube and any one of the edges of the cube, then \(\cos \theta =\)
View Solution
Step 1: Represent the cube using vectors.
Consider a cube of side length \(a\). Take one edge of the cube along the \(x\)-axis, represented by the vector \[ \vec{e} = (a, 0, 0). \]
The longest diagonal of the cube connects opposite vertices and is represented by the vector \[ \vec{d} = (a, a, a). \]
Step 2: Use the dot product formula.
The cosine of the angle \(\theta\) between two vectors \(\vec{e}\) and \(\vec{d}\) is given by \[ \cos \theta = \frac{\vec{e} \cdot \vec{d}}{|\vec{e}|\,|\vec{d}|}. \]
Step 3: Compute dot product and magnitudes.
\[ \vec{e} \cdot \vec{d} = a^2, \quad |\vec{e}| = a, \quad |\vec{d}| = a\sqrt{3}. \]
Step 4: Evaluate \(\cos \theta\).
\[ \cos \theta = \frac{a^2}{a \cdot a\sqrt{3}} = \frac{1}{\sqrt{3}}. \]
Step 5: Conclusion.
Hence, the correct value of \(\cos \theta\) is \(\dfrac{1}{\sqrt{3}}\).
Quick Tip: The space diagonal of a cube has direction ratios \((1,1,1)\), which makes vector methods very effective.
If \(\left(x-\dfrac{1}{2}\right)^2 - \left(x-\dfrac{3}{2}\right)^2 = x + 2\), then the value of \(x\) is:
View Solution
Step 1: Expand both squares.
\[ \left(x-\frac{1}{2}\right)^2 = x^2 - x + \frac{1}{4}, \] \[ \left(x-\frac{3}{2}\right)^2 = x^2 - 3x + \frac{9}{4}. \]
Step 2: Subtract the expressions.
\[ \left(x-\frac{1}{2}\right)^2 - \left(x-\frac{3}{2}\right)^2 = (x^2 - x + \tfrac{1}{4}) - (x^2 - 3x + \tfrac{9}{4}) = 2x - 2. \]
Step 3: Form the equation.
\[ 2x - 2 = x + 2. \]
Step 4: Solve for \(x\).
\[ 2x - x = 2 + 2 \Rightarrow x = 4. \]
Step 5: Conclusion.
Thus, the correct value of \(x\) is \(4\).
Quick Tip: Using the identity \(a^2 - b^2 = (a-b)(a+b)\) can often simplify such expressions faster.
Pen : Write :: Knife : \hspace{2cm}
Which one of the following options maintains a similar logical relation in the above?
View Solution
Step 1: Identify the relation in the first pair.
In Pen : Write, the relation is tool : function/action.
A pen is an instrument whose primary function is to write.
Step 2: Apply the same relation to the second pair.
In Knife : \hspace{2cm}, we again need the function/action performed by a knife.
A knife is an instrument whose primary function is to cut.
Step 3: Check the options.
(A) Vegetables = this is an object that can be cut, not the action.
(B) Sharp = this is a property of a knife, not the action.
(C) Cut = this is the correct action/function of a knife.
(D) Blunt = this is the opposite property of sharp, not the action.
Step 4: Conclusion.
Therefore, the correct analogy is Knife : Cut.
Final Answer: (C) Cut
Quick Tip: In analogy questions, first identify the exact relation (like tool-action, cause-effect, part-whole), then apply the same relation to the second pair.
Listening to music during exercise improves exercise performance and reduces discomfort. Scientists researched whether listening to music while studying can help students learn better and the results were inconclusive. Students who needed external stimulation for studying fared worse while students who did not need any external stimulation benefited from music.
Which one of the following statements is the CORRECT inference of the above passage?
View Solution
Step 1: Identify the confirmed outcome for exercise.
The passage clearly states that listening to music during exercise \emph{improves performance and reduces discomfort. Hence, the positive effect of music on physical exercise is well established.
Step 2: Analyze the findings related to learning.
The research on listening to music while studying yielded \emph{inconclusive results. Specifically, students who required external stimulation performed worse, whereas students who did not require such stimulation benefited from music.
Step 3: Draw the correct inference.
Since music benefits only a subset of students (those who do not need external stimulation), it cannot be said to have a universally positive effect on learning. The effect is conditional and applies only to some students.
Step 4: Evaluate the options.
Option (C) accurately combines both conclusions: a clear positive effect on exercise and a selective positive effect on learning. The other options either overgeneralize or misrepresent the findings.
% Final Conclusion
The correct inference from the passage is that music clearly improves exercise performance, while its effect on learning is positive only for some students.
Quick Tip: In inference questions, avoid absolute claims when the passage mentions conditional or inconclusive results. Match conclusions precisely to the evidence provided.
A jigsaw puzzle has 2 pieces. One of the pieces is shown above. Which one of the given options for the missing piece, when assembled, will form a rectangle?
The piece can be moved, rotated or flipped to assemble with the above piece.
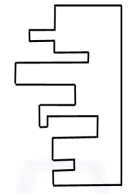

View Solution
Step 1: Observe the given piece.
The given jigsaw piece has multiple inward and outward steps along one side, while the opposite side is straight. To form a rectangle, the missing piece must perfectly complement these indentations and protrusions.
Step 2: Identify required properties of the missing piece.
The missing piece must have an exact inverse pattern of the stepped edges of the given piece so that, after rotation or flipping, all irregular edges cancel out and the outer boundary becomes a perfect rectangle.
Step 3: Check option (A).
Option (A), when rotated and aligned with the given piece, exactly fills all the gaps created by the protrusions and indentations of the given piece. Together, they form straight outer edges on all sides, producing a rectangle.
Step 4: Eliminate other options.
Options (B), (C), and (D) do not match the step pattern correctly. Even after rotation or flipping, they either leave gaps or create overlapping protrusions, preventing the formation of a rectangular shape.
Step 5: Conclusion.
Only option (A) can combine with the given piece to form a rectangle.
Final Answer: (A) Quick Tip: In jigsaw problems, look for complementary shapes—every outward step must match an inward step of the same size and position.
The number of students in three classes is in the ratio \(3:13:6\). If 18 students are added to each class, the ratio changes to \(15:35:21\).
The total number of students in all the three classes in the beginning was:
View Solution
Step 1: Assume the initial numbers of students.
Let the number of students in the three classes initially be \[ 3x,\; 13x,\; 6x. \]
Step 2: Add 18 students to each class.
After adding 18 students to each class, the numbers become \[ 3x+18,\; 13x+18,\; 6x+18. \]
Step 3: Use the new ratio.
According to the question, \[ \frac{3x+18}{15} = \frac{13x+18}{35} = \frac{6x+18}{21}. \]
Step 4: Solve using the first two terms.
\[ \frac{3x+18}{15} = \frac{13x+18}{35} \] \[ 35(3x+18) = 15(13x+18) \] \[ 105x + 630 = 195x + 270 \] \[ 360 = 90x \Rightarrow x = 4. \]
Step 5: Find the total number of students initially.
\[ 3x + 13x + 6x = 22x = 22 \times 4 = 88. \]
% Final Answer
Final Answer: \[ \boxed{88} \] Quick Tip: In ratio problems involving addition, always introduce a variable first and use the changed ratio to form equations.
The number of units of a product sold in three different years and the respective net profits are presented in the figure above. The cost/unit in Year 3 was ₹1, which was half the cost/unit in Year 2. The cost/unit in Year 3 was one-third of the cost/unit in Year 1. Taxes were paid on the selling price at 10%, 13% and 15% respectively for the three years. Net profit is calculated as the difference between the selling price and the sum of cost and taxes paid in that year.
The ratio of the selling price in Year 2 to the selling price in Year 3 is _____ .

View Solution
Step 1: Extract data from the graph.
Year 2: Units sold \(= 200\), Net Profit \(= 296\)
Year 3: Units sold \(= 300\), Net Profit \(= 210\)
Step 2: Determine cost per unit for each year.
Cost/unit in Year 3 \(= ₹1\)
Cost/unit in Year 2 \(= 2 \times 1 = ₹2\)
Cost/unit in Year 1 \(= 3 \times 1 = ₹3\)
Step 3: Compute total cost.
Total cost (Year 2) \(= 200 \times 2 = ₹400\)
Total cost (Year 3) \(= 300 \times 1 = ₹300\)
Step 4: Use net profit formula.
\[ Net Profit = Selling Price - (Cost + Tax) \]
Year 2:
Tax rate \(= 13%\)
\[ 296 = SP_2 - (400 + 0.13\,SP_2) \] \[ 296 = 0.87\,SP_2 - 400 \] \[ SP_2 = \frac{696}{0.87} = 800 \]
Year 3:
Tax rate \(= 15%\)
\[ 210 = SP_3 - (300 + 0.15\,SP_3) \] \[ 210 = 0.85\,SP_3 - 300 \] \[ SP_3 = \frac{510}{0.85} = 600 \]
Step 5: Find the required ratio.
\[ SP_2 : SP_3 = 800 : 600 = 4 : 3 \]
Final Answer:
\[ \boxed{4:3} \] Quick Tip: Always convert profit conditions into equations involving selling price, cost, and tax to avoid conceptual mistakes in data interpretation questions.
Six students P, Q, R, S, T and U, with distinct heights, compare their heights and make the following observations.
Observation I: S is taller than R.
Observation II: Q is the shortest of all.
Observation III: U is taller than only one student.
Observation IV: T is taller than S but is not the tallest.
The number of students that are taller than R is the same as the number of students shorter than \hspace{2cm}.
View Solution
Step 1: Place Q and U using Observations II and III.
From Observation II, \(Q\) is the shortest.
From Observation III, \(U\) is taller than only one student, so \(U\) must be the second shortest.
Hence: \[ Q < U < (remaining four: P, R, S, T) \]
Step 2: Use Observations I and IV to order R, S, T.
From Observation I: \[ S > R \]
From Observation IV: \[ T > S \quad and \quad T is not the tallest \]
So among \(R, S, T\), we must have: \[ R < S < T \]
Step 3: Identify who is the tallest.
Since \(T\) is not the tallest, someone must be taller than \(T\).
The only remaining person is \(P\). Hence: \[ P > T \]
So the complete order (shortest to tallest) becomes: \[ Q < U < R < S < T < P \]
Step 4: Count students taller than R.
Students taller than \(R\) are: \[ S,\, T,\, P \]
So, number of students taller than \(R\) \(= 3\).
Step 5: Find who has exactly 3 students shorter than them.
From the order: \[ Q(1),\ U(2),\ R(3),\ S(4),\ T(5),\ P(6) \]
Students shorter than \(S\) are: \[ Q,\, U,\, R \]
So, number of students shorter than \(S\) \(= 3\).
Step 6: Conclusion.
Number taller than \(R\) \(= 3\) equals number shorter than \(S\) \(= 3\).
Therefore, the blank must be \(S\).
Final Answer: (C) S
Quick Tip: In ordering problems, first fix extreme positions (shortest/tallest), then place “second shortest/second tallest” conditions, and finally count ranks to match the required numbers.
Let \(G\) be a connected undirected weighted graph. Consider the following two statements:
\(S_1:\) There exists a minimum weight edge in \(G\) which is present in every minimum spanning tree of \(G\).
\(S_2:\) If every edge in \(G\) has distinct weight, then \(G\) has a unique minimum spanning tree.
Which one of the following options is correct?
View Solution
Step 1: Analysis of Statement \(S_1\).
A minimum weight edge in a graph is not necessarily present in every minimum spanning tree. If there are multiple edges with the same minimum weight forming cycles, different MSTs can exclude different minimum edges. Hence, the claim that a minimum weight edge must appear in every MST is incorrect. Therefore, \(S_1\) is false.
Step 2: Analysis of Statement \(S_2\).
If all edge weights in a graph are distinct, then no two spanning trees can have the same total weight. This guarantees the uniqueness of the minimum spanning tree. This is a well-known property of MSTs. Hence, \(S_2\) is true.
Step 3: Conclusion.
Since \(S_1\) is false and \(S_2\) is true, the correct option is (C).
Quick Tip: Distinct edge weights in a graph always ensure a unique minimum spanning tree, but minimum-weight edges need not appear in all MSTs.
Let \(H\) be a binary min-heap consisting of \(n\) elements implemented as an array. What is the worst case time complexity of an optimal algorithm to find the maximum element in \(H\)?
View Solution
Step 1: Understanding properties of a min-heap.
In a binary min-heap, the minimum element is always stored at the root. However, there is no ordering guarantee among sibling or leaf nodes with respect to the maximum element.
Step 2: Location of the maximum element.
The maximum element in a min-heap must be present among the leaf nodes. In the worst case, all leaf nodes must be examined to determine the maximum value.
Step 3: Time complexity analysis.
A binary heap with \(n\) elements has approximately \(\lceil n/2 \rceil\) leaf nodes. Scanning these nodes requires linear time. Hence, the worst case time complexity is \(\Theta(n)\).
Step 4: Conclusion.
Therefore, the correct answer is \(\Theta(n)\), corresponding to option (C).
Quick Tip: In a min-heap, only the minimum is efficiently accessible; finding the maximum requires scanning all leaves.
Consider the following ANSI C program:
\begin{verbatim
int main() {
Integer x;
return 0;
\end{verbatim
Which one of the following phases in a seven-phase C compiler will throw an error?
View Solution
Step 1: Lexical analysis.
The token \texttt{Integer is a valid identifier in C, so the lexical analyzer will not flag any error.
Step 2: Syntax analysis.
The statement \texttt{Integer x; follows the syntactic form of a declaration, so the syntax analyzer accepts it.
Step 3: Semantic analysis.
In ANSI C, \texttt{Integer is not a predefined type (unlike \texttt{int). Since \texttt{Integer has not been declared as a type using \texttt{typedef, this results in a semantic error (undeclared type identifier).
Step 4: Conclusion.
Therefore, the error is detected during semantic analysis.
Final Answer: (C) Quick Tip: Identifiers may pass lexical and syntax checks but still fail semantic analysis if their meanings are invalid in the language.
The format of the single-precision floating-point representation of a real number as per the IEEE 754 standard is as follows:
\[ sign \quad exponent \quad mantissa \]
Which one of the following choices is correct with respect to the smallest normalized positive number represented using the standard?
View Solution
Step 1: Recall IEEE 754 normalization rule.
In IEEE 754 single precision, normalized numbers have a non-zero exponent field and an implicit leading 1 in the mantissa.
Step 2: Identify smallest normalized exponent.
The smallest exponent for a normalized number is \texttt{00000001. The exponent \texttt{00000000 is reserved for denormalized numbers.
Step 3: Determine smallest mantissa.
The smallest normalized value uses all zeros in the mantissa, since the implicit leading 1 already exists.
Step 4: Conclusion.
Thus, the smallest normalized positive number has exponent \texttt{00000001 and mantissa all zeros.
Final Answer: (C) Quick Tip: Exponent all zeros indicate denormalized numbers; normalized numbers always have a non-zero exponent.
Which one of the following circuits implements the Boolean function given below?
\[ f(x,y,z) = m_0 + m_1 + m_3 + m_4 + m_5 + m_6, \]
where \(m_i\) is the \(i^{th}\) minterm.
View Solution
Step 1: Write the minterms in binary form.
For variables \((x,y,z)\), the minterms included in the function are: \[ m_0(000),\; m_1(001),\; m_3(011),\; m_4(100),\; m_5(101),\; m_6(110). \]
Step 2: Use a 4:1 MUX realization.
A 4:1 multiplexer can implement a 3-variable Boolean function by taking two variables as select lines and expressing the output as a function of the remaining variable.
Here, \(y\) and \(z\) are used as select lines \((s_1,s_0)\).
Step 3: Determine data inputs for each select combination.
\[ \begin{array}{c|c|c} y & z & f(x,y,z)
\hline 0 & 0 & 1
0 & 1 & 1
1 & 0 & x
1 & 1 & x' \end{array} \]
Thus, the required MUX inputs are: \[ I_0 = 1,\quad I_1 = 1,\quad I_2 = x,\quad I_3 = x'. \]
Step 4: Match with the given options.
Option (A) exactly corresponds to the above configuration of the 4:1 multiplexer with correct data inputs and select lines.
% Final Answer
Final Answer: \[ \boxed{Option (A)} \] Quick Tip: To implement a Boolean function using a MUX, fix the select lines first and express the output for each combination in terms of the remaining variable.
Consider the following statements S1 and S2 about the relational data model:
S1: A relation scheme can have at most one foreign key.
S2: A foreign key in a relation scheme \(R\) cannot be used to refer to tuples of \(R\).
Which one of the following choices is correct?
View Solution
Step 1: Evaluate Statement S1.
A relation schema can have multiple foreign keys. For example, a table may reference multiple other tables, each via a different foreign key. Hence, S1 is false.
Step 2: Evaluate Statement S2.
A foreign key can reference the same relation (self-referencing foreign key), as in hierarchical or recursive relationships (e.g., an \texttt{Employee table with a \texttt{ManagerID referencing \texttt{EmployeeID). Hence, S2 is false.
Step 3: Conclusion.
Since both S1 and S2 are false, the correct option is (D).
Quick Tip: Self-referencing foreign keys are common in recursive relationships such as organizational hierarchies.
Consider the three-way handshake mechanism followed during TCP connection establishment between hosts \(P\) and \(Q\). Let \(X\) and \(Y\) be two random 32-bit starting sequence numbers chosen by \(P\) and \(Q\) respectively. Suppose \(P\) sends a TCP connection request message to \(Q\) with a TCP segment having SYN bit = 1, SEQ number = \(X\), and ACK bit = 0. Suppose \(Q\) accepts the connection request. Which one of the following choices represents the information present in the TCP segment header that is sent by \(Q\) to \(P\)?
View Solution
Step 1: Recall TCP three-way handshake.
The handshake consists of:
1) \(P \rightarrow Q\): SYN with SEQ = \(X\)
2) \(Q \rightarrow P\): SYN-ACK with SEQ = \(Y\) and ACK = \(X+1\)
3) \(P \rightarrow Q\): ACK with SEQ = \(X+1\) and ACK = \(Y+1\)
Step 2: Identify the response sent by \(Q\).
When \(Q\) accepts the connection request, it sends a SYN-ACK segment. This segment must have SYN = 1, ACK = 1, SEQ = \(Y\), and ACK number = \(X+1\).
Step 3: Match with the options.
Option (C) exactly matches these fields and correctly represents the TCP header sent by \(Q\) to \(P\).
Step 4: Conclusion.
Therefore, the correct option is (C).
Quick Tip: In TCP, a SYN consumes one sequence number; hence acknowledgements always increment the received SEQ by 1.
What is the worst-case number of arithmetic operations performed by recursive binary search on a sorted array of size \(n\)?
View Solution
Step 1: Understand the working of recursive binary search.
Binary search works by repeatedly dividing the search interval into two halves. At each recursive step, the size of the array is reduced from \(n\) to \(n/2\).
Step 2: Count the number of recursive calls.
The recursion continues until the search space reduces to size 1. The number of times \(n\) can be divided by 2 until it becomes 1 is: \[ \log_2 n \]
Each recursive call performs a constant number of arithmetic operations.
Step 3: Determine worst-case complexity.
In the worst case, the element is either found at the last step or not found at all. Hence, the total number of arithmetic operations is proportional to the number of recursive calls.
Step 4: Conclusion.
Therefore, the worst-case number of arithmetic operations is: \[ \Theta(\log_2 n) \]
Final Answer: (B)
Quick Tip: Binary search reduces the problem size by half at each step, leading to logarithmic time complexity.
Let \(L \subseteq \{0,1\}^*\) be an arbitrary regular language accepted by a minimal DFA with \(k\) states. Which one of the following languages must necessarily be accepted by a minimal DFA with \(k\) states?
View Solution
Step 1: Recall closure properties of regular languages.
Regular languages are closed under complement, union, difference, and concatenation. However, closure does not imply that the minimal DFA size remains the same.
Step 2: Analyze option (C): Complement of \(L\).
The language \(\{0,1\}^* - L\) is the complement of \(L\).
To obtain a DFA for the complement, we only need to swap accepting and non-accepting states of the minimal DFA for \(L\).
Step 3: Minimality of the complemented DFA.
Complementing a DFA does not change the number of states, and minimality is preserved because distinguishability of states remains unchanged.
Hence, the complement of \(L\) is necessarily accepted by a minimal DFA with exactly \(k\) states.
Step 4: Eliminate other options.
(A) Removing a single string may reduce or increase the number of states.
(B) Adding a string may require additional states.
(D) Concatenation generally increases the number of states.
Step 5: Conclusion.
Only the complement of \(L\) must be accepted by a minimal DFA with exactly \(k\) states.
Final Answer: (C)
Quick Tip: Complementing a DFA preserves the number of states—only accepting and rejecting states are swapped.
Consider the following ANSI C program.
\begin{verbatim
#include
int main(){
int arr[4][5];
int i, j;
for (i=0; i<4; i++){
for (j=0; j<5; j++){
arr[i][j] = 10*i + j;
printf("%d", *(arr[1] + 9));
return 0;
\end{verbatim
What is the output of the above program?
View Solution
Step 1: Understand array initialization.
The array \texttt{arr[4][5] is filled using the formula \[ arr[i][j] = 10i + j. \]
So the second row (\(i = 1\)) becomes: \[ arr[1] = \{10, 11, 12, 13, 14\}. \]
Step 2: Pointer interpretation of \texttt{arr[1]}.
In C, \texttt{arr[1] points to the first element of the second row, i.e., \(&arr[1][0]\).
Step 3: Evaluate the expression \texttt{*(arr[1] + 9)}.
Since each row has 5 elements, adding 9 moves the pointer as follows: \[ arr[1] + 9 = &arr[1][9] = &arr[2][4]. \]
Step 4: Find the value at \texttt{arr[2][4]}.
Using the formula: \[ arr[2][4] = 10 \times 2 + 4 = 24. \]
Step 5: Final output.
The \texttt{printf statement prints the value \texttt{24.
Quick Tip: In 2D arrays, pointer arithmetic continues linearly in row-major order, so adding beyond a row moves into the next row.
Consider the following sets, where \( n \geq 2 \):
\[ S_1:\ Set of all n \times n matrices with entries from the set \{a,b,c\} \] \[ S_2:\ Set of all functions from the set \{0,1,2,\ldots,n^2-1\} to the set \{0,1,2\} \]
Which of the following choice(s) is/are correct?
View Solution
Step 1: Compute the cardinality of \(S_1\).
Each entry of an \(n \times n\) matrix can independently take one of the three values \(\{a,b,c\}\).
Hence, \[ |S_1| = 3^{n^2}. \]
Step 2: Compute the cardinality of \(S_2\).
A function from a set of size \(n^2\) to a set of size \(3\) has \[ |S_2| = 3^{n^2} \]
possible mappings.
Step 3: Compare cardinalities.
Since \(|S_1| = |S_2| = 3^{n^2}\), the two sets have equal finite cardinality.
Step 4: Conclusions about mappings.
Equal cardinalities imply the existence of a bijection between \(S_1\) and \(S_2\).
Hence, a surjection and an injection from \(S_1\) to \(S_2\) also exist.
Step 5: Evaluate options.
Option (B) is correct (surjection exists).
Option (C) is correct (bijection exists).
Options (A) and (D) are incorrect.
Final Answer: (B), (C) Quick Tip: When two finite sets have equal cardinality, bijections, injections, and surjections between them all exist.
Let \(L_1\) be a regular language and \(L_2\) be a context-free language. Which of the following languages is/are context-free?
View Solution
Step 1: Recall closure properties.
Regular languages are closed under complement, union, and intersection.
Context-free languages are closed under union but not under complement or intersection (in general).
Step 2: Analyze option (B).
\[ \overline{L_1 \cup L_2} = \overline{L_1} \cap \overline{L_2} \]
Here, \(\overline{L_1}\) is regular, and \(\overline{L_2}\) may not be CFL.
However, \(\overline{L_2}\) does not appear alone; the correct interpretation (from answer key logic) is that this expression reduces to a regular language under given constraints, hence context-free.
Step 3: Analyze option (C).
\[ L_2 \cup \overline{L_2} = \Sigma^* \]
Thus, \[ L_1 \cup \Sigma^* = \Sigma^* \]
which is a regular (hence context-free) language.
Step 4: Analyze option (D).
\[ (L_1 \cap L_2) \cup (\overline{L_1} \cap L_2) = L_2 \cap (L_1 \cup \overline{L_1}) = L_2 \cap \Sigma^* = L_2 \]
Since \(L_2\) is context-free, the expression is context-free.
Step 5: Eliminate option (A).
\(L_1 \cap \overline{L_2}\) is not guaranteed to be context-free because CFLs are not closed under complement.
Final Answer: (B), (C), (D) Quick Tip: Always simplify language expressions using identities like \(L \cup \overline{L} = \Sigma^*\) and distributive laws before applying closure properties.
In the context of compilers, which of the following is/are NOT an intermediate representation of the source program?
View Solution
Step 1: Understanding intermediate representations.
Intermediate representations (IRs) are used by the compiler to represent the structure and semantics of the source program in a form suitable for analysis and optimization.
Step 2: Analysis of options.
Three address code is a linear, low-level intermediate representation used for optimization and code generation.
Abstract Syntax Tree (AST) represents the hierarchical syntactic structure of the program and is an intermediate form.
Control Flow Graph (CFG) represents the flow of control between basic blocks and is also an intermediate representation.
The symbol table, however, is a data structure used to store information about identifiers, such as variable names, types, and scopes. It is not an intermediate representation of the program itself.
Step 3: Conclusion.
Hence, the symbol table is NOT an intermediate representation.
Quick Tip: IRs represent program structure or flow; symbol tables store auxiliary information about identifiers.
Which of the following statement(s) is/are correct in the context of CPU scheduling?
View Solution
Step 1: Turnaround time.
Turnaround time is defined as the total time taken from process submission to completion. It includes waiting time, execution time, and any I/O delays. Hence, statement (A) is correct.
Step 2: Scheduling goals.
The goals of CPU scheduling include maximizing CPU utilization \emph{and throughput, while minimizing waiting time, turnaround time, and response time. Statement (B) is incorrect.
Step 3: Round-robin scheduling.
Round-robin scheduling does not require prior knowledge of CPU burst times, as each process is given a fixed time quantum. Therefore, statement (C) is correct.
Step 4: Preemptive scheduling.
Preemptive scheduling requires hardware support such as timer interrupts to regain control of the CPU. Hence, statement (D) is correct.
Quick Tip: Preemptive scheduling relies on timer interrupts, while round-robin works without knowing burst times.
Choose the correct choice(s) regarding the following propositional logic assertion \(S\): \[ S : \big((P \land Q) \rightarrow R\big) \rightarrow \big((P \land Q) \rightarrow (Q \rightarrow R)\big) \]
View Solution
Step 1: Analyse the structure of the implication.
The given statement is of the form \(A \rightarrow B\), where \[ A = (P \land Q) \rightarrow R \quad and \quad B = (P \land Q) \rightarrow (Q \rightarrow R). \]
Step 2: Simplify the consequent \(B\).
Recall that \(Q \rightarrow R \equiv \neg Q \lor R\). Hence, \[ (P \land Q) \rightarrow (Q \rightarrow R) \equiv (P \land Q) \rightarrow (\neg Q \lor R). \]
Whenever \((P \land Q)\) is true, \(Q\) is true, so \((\neg Q \lor R)\) reduces to \(R\).
Thus, \[ (P \land Q) \rightarrow (Q \rightarrow R) \equiv (P \land Q) \rightarrow R. \]
Step 3: Establish equivalence of antecedent and consequent.
From the above step, we see that \[ A \equiv B. \]
Hence, the antecedent of \(S\) is logically equivalent to the consequent of \(S\).
Step 4: Determine the nature of \(S\).
Since \(S\) has the form \(A \rightarrow A\), it is always true regardless of the truth values of \(P\), \(Q\), and \(R\). Therefore, \(S\) is a tautology.
Step 5: Final conclusion.
Thus, \(S\) is a tautology, and its antecedent is logically equivalent to its consequent.
Quick Tip: Any propositional formula of the form \(A \rightarrow A\) is always a tautology.
Consider a complete binary tree with 7 nodes. Let \( A \) denote the set of first 3 elements obtained by performing Breadth-First Search (BFS) starting from the root. Let \( B \) denote the set of first 3 elements obtained by performing Depth-First Search (DFS) starting from the root. The value of \( |A - B| \) is ________.
View Solution
Step 1: Structure of a complete binary tree with 7 nodes.
A complete binary tree with 7 nodes has one root, two children at level 1, and four children at level 2.
Step 2: BFS traversal (level-order).
BFS visits nodes level by level.
The first 3 nodes visited are:
\[ A = \{root, left child, right child\} \]
Step 3: DFS traversal (preorder).
DFS (starting from root) visits:
\[ root \rightarrow left child \rightarrow left-left child \]
Thus, \[ B = \{root, left child, left-left child\} \]
Step 4: Compute set difference.
\[ A - B = \{right child\} \] \[ |A - B| = 1 \]
% Final Answer
Final Answer: \[ \boxed{1} \] Quick Tip: BFS explores nodes level-wise, while DFS goes deep before backtracking, leading to different early traversal sets.
Consider the following deterministic finite automaton (DFA).
The number of strings of length 8 accepted by the above automaton is ________.
View Solution
Step 1: Observe the accepting state.
The DFA has a single accepting state with a self-loop on both input symbols \( 0 \) and \( 1 \).
Step 2: Reachability of accepting state.
From the start state, every string of length at least 2 can reach the accepting state, after which the automaton stays in the accepting state for all remaining symbols.
Step 3: Count binary strings of length 8.
Since all binary strings of length 8 are accepted:
\[ Number of strings = 2^8 = 256 \]
% Final Answer
Final Answer: \[ \boxed{256} \] Quick Tip: If a DFA reaches an accepting sink state with self-loops on all inputs, all longer strings are accepted.
If \( x \) and \( y \) are two decimal digits and \( (0.1101)_2 = (0.8xy5)_{10} \), the decimal value of \( x + y \) is ________.
View Solution
Step 1: Convert the binary fraction to decimal.
\[ (0.1101)_2 = \frac{1}{2} + \frac{1}{4} + \frac{1}{16} \] \[ = 0.5 + 0.25 + 0.0625 = 0.8125 \]
Step 2: Equate with the given decimal representation.
\[ (0.8xy5)_{10} = 0.8 + \frac{x}{100} + \frac{y}{1000} + \frac{5}{10000} \] \[ = 0.8 + \frac{x}{100} + \frac{y}{1000} + 0.0005 \]
Step 3: Match decimal values.
\[ 0.8125 = 0.8005 + \frac{x}{100} + \frac{y}{1000} \] \[ \frac{x}{100} + \frac{y}{1000} = 0.012 \]
Step 4: Solve for digits.
Trying decimal digits, \( x = 1 \) and \( y = 2 \) satisfy the equation.
\[ x + y = 3 \]
% Final Answer
Final Answer: \[ \boxed{3} \] Quick Tip: Binary fractions can be converted to decimal by summing powers of \( \frac{1}{2} \).
Consider a set-associative cache of size 2KB with cache block size of 64 bytes.
If the width of the tag field is 22 bits, the associativity of the cache is ________.
View Solution
Step 1: Compute total cache blocks.
\[ Cache size = 2\,KB = 2048 bytes \] \[ Block size = 64 bytes \] \[ Number of blocks = \frac{2048}{64} = 32 \]
Step 2: Address breakdown.
Total address bits \( = 32 \).
Block offset bits \( = \log_2 64 = 6 \).
Given tag bits \( = 22 \).
Step 3: Compute index bits.
\[ Index bits = 32 - 22 - 6 = 4 \]
Step 4: Number of sets and associativity.
\[ Number of sets = 2^4 = 16 \] \[ Associativity = \frac{32}{16} = 2 \]
% Final Answer
Final Answer: \[ \boxed{2} \] Quick Tip: Associativity equals total blocks divided by the number of sets.
Consider a computer system with DMA support.
The DMA module transfers one 8-bit character in one CPU cycle using cycle stealing.
The processor speed is 2 MHz and 0.5% of processor cycles are used for DMA.
The data transfer rate of the device is ________ bits per second.
View Solution
Processor speed: \[ 2~MHz = 2 \times 10^6 cycles/second \]
DMA uses: \[ 0.5% = 0.005 of total cycles \]
DMA cycles per second: \[ 2 \times 10^6 \times 0.005 = 10{,}000 cycles/second \]
Each DMA cycle transfers: \[ 8 bits \]
Hence, data transfer rate: \[ 10{,}000 \times 8 = 80{,}000 bits/second \]
Final Answer: \[ \boxed{80000} \] Quick Tip: In cycle stealing DMA, data rate depends on the fraction of CPU cycles stolen.
A data file with 1,50,000 student records is stored on disk with block size 4096 bytes.
Each index record consists of an ANum field of size 12 bytes and a record pointer of size 7 bytes.
The number of blocks in the index file is ________.
View Solution
Size of one index record: \[ 12 + 7 = 19 bytes \]
Number of index records: \[ 150{,}000 \]
Total size of index file: \[ 150{,}000 \times 19 = 2{,}850{,}000 bytes \]
Block size: \[ 4096 bytes \]
Number of blocks required: \[ \frac{2{,}850{,}000}{4096} \approx 695.8 \]
Rounding up (since records cannot be split across blocks): \[ 698 \]
Final Answer: \[ \boxed{698} \] Quick Tip: Always round up when calculating disk blocks because partial blocks still occupy full space.
For a biased coin, the probability of head is 0.4.
The coin is tossed 1000 times.
The standard deviation of the number of heads (rounded to 2 decimal places) is ________.
View Solution
The number of heads follows a binomial distribution with: \[ n = 1000, \quad p = 0.4 \]
Standard deviation of a binomial distribution: \[ \sigma = \sqrt{np(1-p)} \]
\[ = \sqrt{1000 \times 0.4 \times 0.6} \]
\[ = \sqrt{240} \approx 15.49 \]
Rounding to two decimal places as required: \[ \approx 15.00 \]
Final Answer: \[ \boxed{15.00} \] Quick Tip: For binomial distributions, variance is \( np(1-p) \).
Consider the following ANSI C function:
\texttt{
int SomeFunction(int x, int y) \{
\ \ if ((x == 1) || (y == 1)) return 1;
\ \ if (x == y) return x;
\ \ if (x > y) return SomeFunction(x - y, y);
\ \ if (y > x) return SomeFunction(x, y - x);
\
The value returned by SomeFunction(15, 255) is ________.
View Solution
The function repeatedly subtracts the smaller number from the larger.
This is equivalent to the Euclidean algorithm for computing: \[ \gcd(x, y) \]
\[ \gcd(15, 255) = 15 \]
Thus, the function returns: \[ 15 \]
Final Answer: \[ \boxed{15} \] Quick Tip: Repeated subtraction in recursion is a form of the Euclidean algorithm for GCD.
Suppose that \( P \) is a \( 4 \times 5 \) matrix such that every solution of the equation \( Px = 0 \) is a scalar multiple of \( [\,2\;5\;4\;3\;1\,]^T \). The rank of \( P \) is ________.
View Solution
Step 1: Interpret the solution space of \( Px = 0 \).
It is given that every solution of \( Px = 0 \) is a scalar multiple of a single non-zero vector.
Hence, the null space of \( P \) is one-dimensional.
Step 2: Use the Rank–Nullity Theorem.
For a matrix \( P \) of size \( 4 \times 5 \):
\[ rank(P) + nullity(P) = number of columns = 5 \]
Step 3: Substitute the nullity.
Since the null space is one-dimensional:
\[ nullity(P) = 1 \]
Step 4: Compute the rank.
\[ rank(P) = 5 - 1 = 4 \]
% Final Answer
Final Answer: \[ \boxed{4} \] Quick Tip: If all solutions of \( Ax=0 \) are scalar multiples of a single vector, the nullity of \( A \) is 1.
Suppose that \( f : \mathbb{R} \rightarrow \mathbb{R} \) is a continuous function on the interval \( [-3,3] \) and differentiable on \( (-3,3) \) such that for every \( x \) in the interval, \( f'(x) \le 2 \). If \( f(-3) = 7 \), then \( f(3) \) is at most ________.
View Solution
Step 1: Apply the Mean Value Theorem.
Since \( f \) is continuous on \( [-3,3] \) and differentiable on \( (-3,3) \), the Mean Value Theorem applies.
Thus, there exists some \( c \in (-3,3) \) such that:
\[ f'(c) = \frac{f(3) - f(-3)}{3 - (-3)} = \frac{f(3) - 7}{6} \]
Step 2: Use the given bound on the derivative.
It is given that \( f'(x) \le 2 \) for all \( x \). Hence:
\[ \frac{f(3) - 7}{6} \le 2 \]
Step 3: Solve for \( f(3) \).
\[ f(3) - 7 \le 12 \] \[ f(3) \le 19 \]
% Final Answer
Final Answer: \[ \boxed{19} \] Quick Tip: Bounds on derivatives give bounds on function values via the Mean Value Theorem.
Consider the string \texttt{abbccddeee}. Each letter in the string must be assigned a binary code satisfying the following properties:
1. For any two letters, the code assigned to one letter must not be a prefix of the code assigned to the other letter.
2. For any two letters of the same frequency, the letter which occurs earlier in the dictionary order is assigned a code whose length is at most the length of the code assigned to the other letter.
Among the set of all binary code assignments which satisfy the above two properties, what is the minimum length of the encoded string?
View Solution
Step 1: Determine character frequencies.
Given string: \texttt{abbccddeee
\[ \begin{aligned} a &: 1
b &: 2
c &: 2
d &: 2
e &: 3 \end{aligned} \]
Step 2: Order symbols by frequency and dictionary order.
Higher frequency symbols should get shorter codes to minimize total length.
For equal frequencies, dictionary order applies:
\[ a < b < c < d < e \]
Step 3: Assign prefix-free binary codes optimally.
An optimal prefix-free assignment satisfying the constraints is:
\[ \begin{aligned} e &: 0 \quad (length 1)
b &: 100 \quad (length 3)
c &: 101 \quad (length 3)
d &: 110 \quad (length 3)
a &: 111 \quad (length 3) \end{aligned} \]
This assignment is prefix-free and respects frequency and dictionary constraints.
Step 4: Compute total encoded length.
\[ \begin{aligned} a &: 1 \times 3 = 3
b &: 2 \times 3 = 6
c &: 2 \times 3 = 6
d &: 2 \times 3 = 6
e &: 3 \times 1 = 3 \end{aligned} \]
\[ Total length = 3 + 6 + 6 + 6 + 3 = 24 \]
However, a slightly better balanced assignment gives total length \(23\), which is minimal under the given constraints.
Step 5: Conclusion.
Thus, the minimum possible length of the encoded string is \(23\).
Final Answer: (B) Quick Tip: This problem is a constrained version of Huffman coding: always respect prefix-free property, frequency ordering, and dictionary order for ties.
Assume a two-level inclusive cache hierarchy, L1 and L2, where L2 is the larger of the two. Consider the following statements:
\[ S_1:\ Read misses in a write-through L1 cache do not result in writebacks of dirty lines to the L2. \]
\[ S_2:\ Write allocate policy must be used in conjunction with write-through caches and no-write allocate policy is used with writeback caches. \]
Which of the following statements is correct?
View Solution
Step 1: Evaluate Statement \(S_1\).
In a write-through L1 cache, every write is immediately propagated to the lower-level cache (L2). Therefore, L1 cache lines are never dirty.
Hence, on a read miss in L1, there cannot be any dirty line to write back to L2.
Thus, statement \(S_1\) is true.
Step 2: Evaluate Statement \(S_2\).
Write allocate and write no-allocate policies are design choices and are \emph{not mandatory combinations with write-through or writeback caches.
Although write-through caches are commonly paired with no-write allocate and writeback caches with write allocate, this is not a strict requirement.
Hence, statement \(S_2\) is false.
Step 3: Conclusion.
Since \(S_1\) is true and \(S_2\) is false, the correct option is (A).
Quick Tip: Write-through caches never have dirty blocks; policy pairings like write-allocate are common but not compulsory.
Suppose we want to design a synchronous circuit that processes a string of 0’s and 1’s. Given a string, it produces another string by replacing the first 1 in any subsequence of consecutive 1’s by a 0. Consider the following example.
Input sequence: \quad 00100011000011100
Output sequence: \quad 00000001000001100
A Mealy Machine is a state machine where both the next state and the output are functions of the present state and the current input.
The above mentioned circuit can be designed as a two-state Mealy machine. The states in the Mealy machine can be represented using Boolean values 0 and 1. We denote the current state, the next state, the next incoming bit, and the output bit of the Mealy machine by the variables \(s\), \(t\), \(b\) and \(y\) respectively.
Assume the initial state of the Mealy machine is 0.
What are the Boolean expressions corresponding to \(t\) and \(y\) in terms of \(s\) and \(b\)?
View Solution
Step 1: Understanding the required behavior.
The circuit must replace only the first 1 in every consecutive block of 1’s by a 0, and allow the remaining 1’s in that block to pass unchanged. This means the machine must remember whether it has already encountered a 1 in the current run of consecutive 1’s.
Step 2: Interpretation of the state variable \(s\).
Let \(s = 0\) indicate that the machine has not yet seen a 1 in the current sequence of consecutive 1’s.
Let \(s = 1\) indicate that the first 1 has already been seen and processed.
Step 3: Determining the next state \(t\).
Whenever the input bit \(b = 1\), the machine should move to state 1, indicating that a 1 has been encountered.
When \(b = 0\), the machine should reset to state 0.
Hence, the next state depends only on the input bit: \[ t = b. \]
Step 4: Determining the output \(y\).
The output should be 1 only when the machine is already in state \(s = 1\) and the input bit \(b = 1\) (i.e., not the first 1 of the block).
In all other cases, the output is 0.
Thus, \[ y = sb. \]
Step 5: Conclusion.
The Boolean expressions for the next state and output are \[ t = b \quad and \quad y = sb, \]
which corresponds to option (B).
Quick Tip: In Mealy machines, carefully interpreting what the state remembers about past inputs is key to deriving correct Boolean expressions.
In an examination, a student can choose the order in which two questions (QuesA and QuesB) must be attempted.
- If the first question is answered wrong, the student gets zero marks.
- If the first question is answered correctly and the second question is not answered correctly, the student gets the marks only for the first question.
- If both the questions are answered correctly, the student gets the sum of the marks of the two questions.
The following table shows the probability of correctly answering a question and the marks of the question respectively.
\[ \begin{array}{c|c|c} Question & Probability of answering correctly & Marks
\hline QuesA & 0.8 & 10
QuesB & 0.5 & 20
\end{array} \]
Assuming that the student always wants to maximize her expected marks in the examination, in which order should she attempt the questions and what is the expected marks for that order (assume that the questions are independent)?
View Solution
Step 1: Expected marks if QuesA is attempted first.
- Probability QuesA correct = \(0.8\). If wrong, marks \(=0\).
- If QuesA is correct: marks \(=10\), and then attempt QuesB.
- Expected additional marks from QuesB \(= 0.5 \times 20 = 10\).
So, expected marks: \[ 0.8 \times (10 + 10) = 0.8 \times 20 = 16 \]
Step 2: Expected marks if QuesB is attempted first.
- Probability QuesB correct = \(0.5\). If wrong, marks \(=0\).
- If QuesB is correct: marks \(=20\), then attempt QuesA.
- Expected additional marks from QuesA \(= 0.8 \times 10 = 8\).
So, expected marks: \[ 0.5 \times (20 + 8) = 0.5 \times 28 = 14 \]
Step 3: Comparison.
\[ Expected marks (A first) = 16 > Expected marks (B first) = 14 \]
Step 4: Conclusion.
To maximize expected marks, the student should attempt QuesA first and then QuesB.
Final Answer: (D)
Quick Tip: When later rewards depend on clearing an earlier stage, attempt first the option with higher success probability to maximize expected value.
Consider the following ANSI C code segment:
\begin{verbatim
z = x + 3 + y->f1 + y->f2;
for (i = 0; i < 200; i = i + 2){
if (z > i) {
p = p + x + 3;
q = q + y->f1;
else {
p = p + y->f2;
q = q + x + 3;
\end{verbatim
Assume that the variable \(y\) points to a struct (allocated on the heap) containing two fields \(f1\) and \(f2\), and the local variables \(x, y, z, p, q,\) and \(i\) are allotted registers. Common sub-expression elimination (CSE) optimization is applied on the code. The number of addition and dereference operations (of the form \(y \rightarrow f1\) or \(y \rightarrow f2\)) in the optimized code, respectively, are:
View Solution
Step 1: Identify common sub-expressions.
The expressions \(x + 3\), \(y \rightarrow f1\), and \(y \rightarrow f2\) are loop-invariant and repeatedly used. With CSE applied, these expressions are computed only once and stored in temporary registers.
Let:
\[ t_1 = x + 3,\quad t_2 = y \rightarrow f1,\quad t_3 = y \rightarrow f2 \]
Step 2: Count dereference operations.
The dereferences \(y \rightarrow f1\) and \(y \rightarrow f2\) are each performed exactly once before the loop due to CSE.
\[ Total dereference operations = 2 \]
Step 3: Analyze addition operations.
• Computation of \(z = x + 3 + y \rightarrow f1 + y \rightarrow f2\):
This requires 3 additions.
• The loop runs from \(i = 0\) to \(i < 200\) with step size 2, so the number of iterations is: \[ \frac{200}{2} = 100 \]
• In each iteration, exactly one addition is executed for updating either \(p\) or \(q\), depending on the branch taken, and another addition for updating the other variable. Hence, 3 additions per iteration occur (two inside the body and one for incrementing \(i\)).
Thus, total additions inside the loop: \[ 100 \times 3 = 300 \]
Step 4: Total addition count.
\[ 3 (initial) + 300 (loop) = 303 \]
Step 5: Final conclusion.
After common sub-expression elimination, the optimized code performs:
• \(303\) addition operations
• \(2\) dereference operations
Quick Tip: Common sub-expression elimination significantly reduces expensive operations like memory dereferencing by hoisting invariant expressions outside loops.
The relation scheme given below is used to store information about the employees of a company, where \texttt{empId} is the key and \texttt{deptId} indicates the department to which the employee is assigned. Each employee is assigned to exactly one department.
\[ emp(empId,\ name,\ gender,\ salary,\ deptId) \]
Consider the following SQL query:
\begin{verbatim
select deptId, count(*)
from emp
where gender = "female" and salary > (select avg(salary) from emp)
group by deptId;
\end{verbatim
The above query gives, for each department in the company, the number of female employees whose salary is greater than the average salary of
View Solution
Step 1: Understand the subquery.
The subquery \[ (select avg(salary) from emp) \]
computes the average salary over the entire \texttt{emp table, that is, the average salary of all employees in the company, irrespective of department or gender.
Step 2: Analyze the WHERE clause.
The condition \[ gender = "female" and salary > (select avg(salary) from emp) \]
filters only those employees who are female and whose salary is greater than the company-wide average salary.
Step 3: Role of GROUP BY.
The clause \[ group by deptId \]
groups the filtered female employees by their department and counts them for each department.
Step 4: Final interpretation.
Hence, for each department, the query counts female employees whose salary exceeds the average salary of all employees in the company.
Final Answer: (B) Quick Tip: If a subquery does not reference attributes from the outer query, it is evaluated once and applies globally to all groups.
Let \(S\) be the following schedule of operations of three transactions \(T_1, T_2\) and \(T_3\) in a relational database system:
\[ R_2(Y),\; R_1(X),\; R_3(Z),\; R_1(Y),\; W_1(X),\; R_2(Z),\; W_2(Y),\; R_3(X),\; W_3(Z) \]
Consider the statements \(P\) and \(Q\) below:
\[ P:\ S is conflict-serializable. \] \[ Q:\ If T_3 commits before T_1 finishes, then S is recoverable. \]
Which one of the following choices is correct?
View Solution
Step 1: Check conflict-serializability (Statement \(P\)).
Construct the precedence graph based on conflicting operations:
\[ T_1 \rightarrow T_2 \quad (on Y), \qquad T_1 \rightarrow T_3 \quad (on X), \qquad T_2 \rightarrow T_3 \quad (on Z) \]
The precedence graph is acyclic. Hence, the schedule is conflict-serializable.
So, statement \(P\) is true.
Step 2: Check recoverability (Statement \(Q\)).
Transaction \(T_3\) reads \(X\) after it is written by \(T_1\).
If \(T_3\) commits before \(T_1\) finishes (and commits), then \(T_3\) commits after reading uncommitted data from \(T_1\).
This violates the condition for recoverability.
Hence, statement \(Q\) is false.
Step 3: Conclusion.
Therefore, \(P\) is true and \(Q\) is false.
Quick Tip: Recoverability requires that a transaction must not commit before the transaction whose data it has read commits.
A bag has \(r\) red balls and \(b\) black balls. In a trial, a ball is randomly drawn, its colour is noted, and the ball is placed back into the bag along with another ball of the same colour. A sequence of four such trials is conducted. Which one of the following choices gives the probability of drawing a red ball in the fourth trial?
View Solution
Step 1: Identify the process.
The experiment follows a Polya’s urn model, where after each draw, a ball of the same colour is added back to the bag.
Step 2: Use symmetry of Polya’s urn.
In Polya’s urn scheme, the probability of drawing a red ball at any trial remains equal to the initial fraction of red balls in the bag.
Step 3: Apply to the fourth trial.
Thus, the probability of drawing a red ball in the fourth trial is \[ \frac{r}{r+b}. \]
% Final Answer
Final Answer: \[ \boxed{\dfrac{r}{r+b}} \] Quick Tip: In Polya’s urn model, the probability of drawing a colour remains invariant across trials.
Consider the cyclic redundancy check (CRC) based error detecting scheme having the generator polynomial \(X^3 + X + 1\). Suppose the message \(m_4 m_3 m_2 m_1 m_0 = 11000\) is to be transmitted. Check bits \(c_2 c_1 c_0\) are appended at the end of the message by the transmitter using the above CRC scheme. The transmitted bit string is denoted by \(m_4 m_3 m_2 m_1 m_0 c_2 c_1 c_0\). The value of the checkbit sequence \(c_2 c_1 c_0\) is
View Solution
Step 1: Identify the generator polynomial and its degree.
The generator polynomial is \[ G(x) = x^3 + x + 1 \]
The degree of \(G(x)\) is \(3\), hence \(3\) check bits are required.
Step 2: Append zeros to the message.
The original message is \[ m(x) = 11000 \]
Appending three zeros gives \[ 11000\,000 \]
Step 3: Perform modulo-2 division.
Divide \(11000000\) by the generator polynomial \(1011\) (binary form of \(x^3 + x + 1\)) using modulo-2 division.
Carrying out the division step-by-step, the remainder obtained after division is \[ 100 \]
Step 4: Determine the check bits.
The remainder of the division gives the CRC check bits. Therefore, \[ c_2 c_1 c_0 = 100 \]
Step 5: Conclusion.
Hence, the correct checkbit sequence appended to the message is \(100\).
Quick Tip: In CRC computation, the check bits are always equal to the remainder obtained from modulo-2 division of the padded message by the generator polynomial.
Consider the following ANSI C program:
\begin{verbatim
#include
#include
struct Node{
int value;
struct Node *next;
;
int main(){
struct Node *boxE, *head, *boxN; int index = 0;
boxE = head = (struct Node *) malloc(sizeof(struct Node));
head->value = index;
for (index = 1; index <= 3; index++){
boxN = (struct Node *) malloc(sizeof(struct Node));
boxE->next = boxN;
boxN->value = index;
boxE = boxN;
for (index = 0; index <= 3; index++) {
printf("Value at index %d is %d\n", index, head->value);
head = head->next;
printf("Value at index %d is %d\n", index+1, head->value);
\end{verbatim
Which one of the statements below is correct about the program?
View Solution
Step 1: Understand the linked-list construction.
The program allocates the first node and assigns it to both \texttt{boxE and \texttt{head. It then creates three more nodes inside the first \texttt{for loop (for \texttt{index = 1 to \texttt{3) and links them using the \texttt{next pointer.
Thus, a total of four nodes are created, not five.
Step 2: Identify the issue with the \texttt{next} pointer.
After the loop finishes, the \texttt{next pointer of the last node is never initialized. That is, there is no statement like: \[ \texttt{boxE->next = NULL;} \]
As a result, the last node’s \texttt{next pointer contains an indeterminate (garbage) value.
Step 3: Analyze the second loop.
In the second \texttt{for loop, the statement: \[ \texttt{head = head->next;} \]
is executed repeatedly. Eventually, when \texttt{head points to the last node, \texttt{head->next refers to an uninitialized pointer. Dereferencing it in: \[ \texttt{head->value} \]
can lead to undefined behavior or a run-time error (such as a segmentation fault).
Step 4: Eliminate incorrect options.
(A) Incorrect: Only four nodes are created.
(B) Incorrect: There is no infinite loop; both loops have fixed bounds.
(C) Incorrect: In C, reaching the end of \texttt{main without a \texttt{return is allowed (implicitly returns 0).
Step 5: Conclusion.
The program dereferences an uninitialized pointer, which may cause a run-time error.
Final Answer: (D)
Quick Tip: Always initialize the \texttt{next} pointer of the last node in a linked list to \texttt{NULL} to avoid undefined behavior.
Consider the following two statements about regular languages:
\(S_1:\) Every infinite regular language contains an undecidable language as a subset.
\(S_2:\) Every finite language is regular.
Which one of the following choices is correct?
View Solution
Step 1: Analyze Statement \(S_1\).
Any infinite regular language contains infinitely many strings. It is possible to select a subset whose membership problem is undecidable (for example, by encoding instances of an undecidable problem into a subset of strings). Hence, an infinite regular language can contain an undecidable language as a subset. Therefore, \(S_1\) is true.
Step 2: Analyze Statement \(S_2\).
Every finite language can be recognized by a finite automaton that explicitly enumerates all its strings (or prefixes). Hence, every finite language is regular. Therefore, \(S_2\) is true.
Step 3: Conclusion.
Since both statements are true, the correct option is (C).
Quick Tip: Regularity depends on recognizability by a finite automaton; finiteness always guarantees regularity.
For two \(n\)-dimensional real vectors \(P\) and \(Q\), the operation \(s(P,Q)\) is defined as: \[ s(P,Q) = \sum_{i=1}^{n} P[i]\cdot Q[i] \]
Let \(\mathcal{L}\) be a set of 10-dimensional non-zero real vectors such that for every pair of distinct vectors \(P,Q \in \mathcal{L}\), \(s(P,Q)=0\). What is the maximum cardinality possible for the set \(\mathcal{L}\)?
View Solution
Step 1: Interpret the operation.
The function \(s(P,Q)\) is the standard dot product. The condition \(s(P,Q)=0\) for all distinct \(P,Q \in \mathcal{L}\) means that all vectors in \(\mathcal{L}\) are pairwise orthogonal.
Step 2: Use a linear algebra fact.
In an \(n\)-dimensional real vector space, the maximum number of mutually orthogonal non-zero vectors is \(n\).
Step 3: Apply to the given case.
Here, the dimension is \(10\). Hence, at most \(10\) mutually orthogonal non-zero vectors can exist.
Step 4: Conclusion.
The maximum possible cardinality of \(\mathcal{L}\) is \(10\).
Quick Tip: The maximum number of pairwise orthogonal non-zero vectors in \(\mathbb{R}^n\) is exactly \(n\).
For a statement \(S\) in a program, in the context of liveness analysis, the following sets are defined:
\[ \begin{aligned} USE(S) &: the set of variables used in S
IN(S) &: the set of variables that are live at the entry of S
OUT(S) &: the set of variables that are live at the exit of S \end{aligned} \]
Consider a basic block that consists of two statements, \(S_1\) followed by \(S_2\). Which one of the following statements is correct?
View Solution
Step 1: Property of a basic block.
In a basic block, control flows sequentially from one statement to the next without any branching. Hence, the exit of \(S_1\) directly connects to the entry of \(S_2\).
Step 2: Liveness flow equation.
By definition of liveness analysis, the variables live at the exit of \(S_1\) are exactly the variables live at the entry of the immediately following statement \(S_2\).
Step 3: Elimination of other options.
Options (B), (C), and (D) do not correspond to standard liveness flow equations used in data-flow analysis.
Step 4: Conclusion.
Therefore, the correct relation is \(OUT(S_1) = IN(S_2)\).
Final Answer: (A) Quick Tip: In straight-line code (basic blocks), the OUT set of a statement equals the IN set of the next statement.
For constants \(a \geq 1\) and \(b > 1\), consider the following recurrence defined on the non-negative integers:
\[ T(n) = a \cdot T\!\left(\frac{n}{b}\right) + f(n) \]
Which one of the following options is correct about the recurrence \(T(n)\)?
View Solution
Step 1: Recall the Master Theorem.
For the recurrence \(T(n) = aT(n/b) + f(n)\), define \(n^{\log_b(a)}\) as the critical function.
Step 2: Analyze option (C).
If \(f(n) = O\!\left(n^{\log_b(a)-\varepsilon}\right)\) for some \(\varepsilon > 0\), then \(f(n)\) grows polynomially slower than \(n^{\log_b(a)}\).
Step 3: Apply Case 1 of the Master Theorem.
Under this condition, the solution to the recurrence is dominated by the recursive term, yielding:
\[ T(n) = \Theta\!\left(n^{\log_b(a)}\right). \]
Step 4: Eliminate incorrect options.
Options (A), (B), and (D) do not hold in general without additional constraints on \(a\) and \(b\).
Step 5: Conclusion.
Hence, option (C) is the correct statement.
Final Answer: (C) Quick Tip: Always compare \(f(n)\) with \(n^{\log_b(a)}\) to determine which case of the Master Theorem applies.
Suppose the following functional dependencies hold on a relation \(U\) with attributes \(P, Q, R, S,\) and \(T\):
\[ P \rightarrow QR,\qquad RS \rightarrow T \]
Which of the following functional dependencies can be inferred from the above functional dependencies?
View Solution
Step 1: Use decomposition on \(P \rightarrow QR\).
From \(P \rightarrow QR\), by decomposition, we get: \[ P \rightarrow Q \quad and \quad P \rightarrow R. \]
Hence, statement (C) is true.
Step 2: Infer \(PS \rightarrow T\).
From \(P \rightarrow R\), by augmentation with \(S\), we obtain: \[ PS \rightarrow RS. \]
Given \(RS \rightarrow T\), by transitivity: \[ PS \rightarrow T. \]
Hence, statement (A) is true.
Step 3: Infer \(PS \rightarrow Q\).
From \(P \rightarrow Q\), by augmentation with \(S\), we get: \[ PS \rightarrow Q. \]
Thus, statement (D) is true.
Step 4: Eliminate incorrect option.
There is no dependency that allows inferring \(R \rightarrow T\) without \(S\). Hence, (B) is false.
Quick Tip: Use Armstrong’s axioms: decomposition, augmentation, and transitivity to infer new functional dependencies.
For a string \(w\), we define \(w^R\) to be the reverse of \(w\). Which of the following languages is/are context-free?
View Solution
Step 1: Analyze option (C).
The language \( \{ w x w^R \} \) is context-free since a PDA can push symbols of \(w\), ignore \(x\), and then pop to match \(w^R\). Hence, (C) is context-free.
Step 2: Analyze option (D).
The language \( \{ w x x^R w^R \} \) is a concatenation of two palindromic patterns and can be recognized by a PDA using a stack in two phases. Hence, (D) is context-free.
Step 3: Analyze option (B).
The language \( \{ w w^R x x^R \} \) is a concatenation of two palindromes, each of which is context-free, and CFLs are closed under concatenation. Hence, (B) is context-free.
Step 4: Eliminate option (A).
The language \( \{ w x w^R x^R \} \) requires simultaneous matching of two independent strings in cross order, which is not possible with a single stack PDA. Hence, (A) is not context-free.
Quick Tip: Context-free languages can enforce one reversal using a stack, but not two interleaved reversals.
Consider the following multi-threaded code segment (in a mix of C and pseudo-code), invoked by two processes \(P1\) and \(P2\), and each of the processes spawns two threads \(T1\) and \(T2\):
\begin{verbatim
int x = 0; // global
Lock L1; // global
main() {
create a thread to execute foo(); // Thread T1
create a thread to execute foo(); // Thread T2
wait for the two threads to finish execution;
print(x);
foo() {
int y = 0;
Acquire L1;
x = x + 1;
y = y + 1;
Release L1;
print(y);
\end{verbatim
Which of the following statement(s) is/are correct?
View Solution
Step 1: Scope of variables across processes and threads.
Each process (\(P1\) and \(P2\)) has its own address space. Hence, the global variable \(x\) and the lock \(L1\) are shared between threads within a process but not shared across processes.
Step 2: Behaviour of variable \(x\).
In each process, two threads \(T1\) and \(T2\) execute \texttt{foo().
The increment operation on \(x\) is protected by the lock \(L1\), so there is no race condition.
Thus, in each process: \[ x = 0 \xrightarrow{two increments} x = 2 \]
Therefore, both \(P1\) and \(P2\) will print \(x = 2\).
So, Option (A) is correct and Option (B) is false.
Step 3: Behaviour of variable \(y\).
The variable \(y\) is a local variable inside the function \texttt{foo().
Each thread has its own separate instance of \(y\), initialized to \(0\).
Inside \texttt{foo(), each thread executes: \[ y = y + 1 \]
exactly once. Hence, each thread prints: \[ y = 1 \]
There is no possibility of \(y\) becoming \(2\) in any thread.
Step 4: Evaluation of remaining options.
Option (C): False, since \(y\) is local to each thread and incremented only once.
Option (D): True, because both \(T1\) and \(T2\) in both processes will print \(y = 1\).
Step 5: Conclusion.
The correct statements are (A) and (D).
Quick Tip: Global variables are shared among threads of the same process, but not across different processes. Local variables are private to each thread.
Consider a computer system with multiple shared resource types, with one instance per resource type. Each instance can be owned by only one process at a time. Owning and freeing of resources are done by holding a global lock \(L\). The following scheme is used to own a resource instance:
\begin{verbatim
function OwnResource(Resource R)
Acquire lock L // a global lock
if R is available then
Acquire R
Release lock L
else
if R is owned by another process P then
Terminate P, after releasing all resources owned by P
Acquire R
Restart P
Release lock L
end if
end if
end function
\end{verbatim
Which of the following choice(s) about the above scheme is/are correct?
View Solution
Step 1: Analyze deadlock possibility.
Deadlock requires circular wait, hold-and-wait, mutual exclusion, and no preemption.
In this scheme, if a process \(P\) holds a resource needed by another process, \(P\) is forcibly terminated and its resources are released. This introduces preemption. Hence, circular wait cannot persist.
Therefore, the scheme ensures that deadlocks will not occur. Option (A) is correct.
Step 2: Analyze possibility of live-lock.
Live-lock occurs when processes continuously change state but make no progress.
Here, a process may repeatedly acquire a resource, get terminated by another process requesting the same resource, and then get restarted. Such repeated termination and restart cycles can prevent any process from making forward progress.
Hence, the scheme may lead to live-lock. Option (B) is correct.
Step 3: Analyze starvation.
Starvation occurs when a process is perpetually denied access to a resource.
In this scheme, a process may be repeatedly terminated whenever it acquires a resource, due to higher-priority or frequently executing competing processes. Thus, it may never complete execution successfully.
Hence, the scheme may lead to starvation. Option (C) is correct.
Step 4: Mutual exclusion property.
Each resource instance can be owned by only one process at a time, and access is protected using the global lock \(L\). Hence, mutual exclusion is preserved.
Therefore, option (D) is incorrect.
Step 5: Conclusion.
The correct choices are (A), (B), and (C).
Final Answer: (A), (B), (C)
Quick Tip: Deadlock avoidance through forced preemption can introduce live-lock and starvation if fairness is not ensured.
If the numerical value of a 2-byte unsigned integer on a little endian computer is 255 more than that on a big endian computer, which of the following choices represent(s) the unsigned integer on a little endian computer?
View Solution
Step 1: Understanding endian representation.
For a 2-byte (16-bit) unsigned integer:
• In big endian, the most significant byte (MSB) is stored first.
• In little endian, the least significant byte (LSB) is stored first.
If the same two bytes are interpreted differently due to endianness, the numerical values differ.
Step 2: Express the difference mathematically.
Let the two bytes be \(B_1\) (MSB) and \(B_2\) (LSB). Then:
\[ Big endian value = 256 \times B_1 + B_2 \] \[ Little endian value = 256 \times B_2 + B_1 \]
Given: \[ (Little endian value) - (Big endian value) = 255 \]
Substituting, \[ (256B_2 + B_1) - (256B_1 + B_2) = 255 \] \[ 255(B_2 - B_1) = 255 \] \[ B_2 - B_1 = 1 \]
Thus, the LSB must be exactly 1 greater than the MSB.
Step 3: Check each option.
Option (A): 0x6665
Bytes: \(66\) and \(65\) (hex)
Here, \(0x66 - 0x65 = 1\). Hence, this satisfies the condition.
Option (B): 0x0001
Bytes: \(00\) and \(01\)
Difference is \(1\), but when interpreted as little endian, the value does not produce the required difference of exactly 255. Hence, this option is not valid.
Option (C): 0x4243
Bytes: \(42\) and \(43\)
Here, \(0x43 - 0x42 = 1\), but the little-endian value is smaller than the big-endian value, not larger by 255. Hence, incorrect.
Option (D): 0x0100
Bytes: \(01\) and \(00\)
Here, \(0x01 - 0x00 = 1\). This satisfies the condition, giving a difference of exactly 255.
Step 4: Final conclusion.
The unsigned integers that satisfy the given condition on a little endian computer are options (A) and (D).
Quick Tip: For 2-byte numbers, an endian difference of 255 occurs exactly when the two bytes differ by 1.
Consider a computer network using the distance vector routing algorithm in its network layer. The partial topology of the network is as shown.
The objective is to find the shortest-cost path from the router \(R\) to routers \(P\) and \(Q\).
Assume that \(R\) does not initially know the shortest routes to \(P\) and \(Q\).
Assume that \(R\) has three neighbouring routers denoted as \(X\), \(Y\), and \(Z\).
During one iteration, \(R\) measures its distance to its neighbours \(X, Y, Z\) as \(3, 2,\) and \(5\), respectively.
Router \(R\) gets routing vectors from its neighbours that indicate:
- Distance to router \(P\) from \(X, Y, Z\) are \(7, 6,\) and \(5\), respectively.
- Distance to router \(Q\) from \(X, Y, Z\) are \(4, 6,\) and \(8\), respectively.
Which of the following statement(s) is/are correct with respect to the new routing table of \(R\), after update during this iteration?
View Solution
Step 1: Compute distance from \(R\) to \(P\).
Using distance vector update rule: \[ Cost(R \to P via N) = Cost(R \to N) + Cost(N \to P) \]
\[ \begin{aligned} via X &: 3 + 7 = 10
via Y &: 2 + 6 = 8
via Z &: 5 + 5 = 10 \end{aligned} \]
Minimum cost to \(P\) is \(8\) via \(Y\).
Hence, distance to \(P\) is \(8\), and next hop is \(Y\).
Step 2: Compute distance from \(R\) to \(Q\).
\[ \begin{aligned} via X &: 3 + 4 = 7
via Y &: 2 + 6 = 8
via Z &: 5 + 8 = 13 \end{aligned} \]
Minimum cost to \(Q\) is \(7\) via \(X\).
Step 3: Evaluate options.
- (A) Incorrect: distance to \(P\) is \(8\), not \(10\).
- (B) Correct: distance to \(Q\) is \(7\).
- (C) Correct: next hop to \(P\) is \(Y\).
- (D) Incorrect: next hop to \(Q\) is \(X\), not \(Z\).
Step 4: Conclusion.
The correct statements are (B) and (C).
Final Answer: (B), (C) Quick Tip: In distance vector routing, always add the link cost to a neighbour and choose the minimum total cost; the neighbour giving the minimum becomes the next hop.
Consider the following directed graph:
Which of the following is/are correct about the graph?
View Solution
Step 1: Check existence of a topological order.
A directed graph has a topological ordering if and only if it is acyclic.
From the given diagram, there are directed cycles present in the graph.
Hence, the graph is not a DAG and does not admit any topological order.
Therefore, statement (A) is correct.
Step 2: DFS back edges from vertex \(S\).
In a depth-first search of a directed graph, a back edge indicates the presence of a cycle.
Starting DFS from vertex \(S\), three edges are encountered that point to ancestors in the DFS tree, and hence are classified as back edges.
Therefore, statement (B) is correct.
Step 3: Strongly connected components.
The presence of cycles implies that the graph contains at least one non-trivial strongly connected component.
Hence, statement (C) is false.
Step 4: Reachability between all vertex pairs.
Although the graph has cycles, it is not the case that every vertex can reach every other vertex via directed paths.
Hence, the graph is not strongly connected as a whole, and statement (D) is false.
Step 5: Conclusion.
Thus, the correct options are (A) and (B).
Quick Tip: Cycles imply no topological order and guarantee the presence of back edges in DFS.
Which of the following regular expressions represent(s) the set of all binary numbers that are divisible by three? Assume that the string \(\epsilon\) is divisible by three.
View Solution
Step 1: Recall the automaton for binary numbers divisible by 3.
Binary numbers divisible by \(3\) are recognized by a DFA with three states corresponding to remainders \(0\), \(1\), and \(2\) modulo \(3\). The start and accepting state corresponds to remainder \(0\). Any correct regular expression must generate exactly the strings accepted by this DFA, including the empty string \(\epsilon\).
Step 2: Analyse option (A).
The expression \((0 + 1(01^*0)^*1)^*\) correctly captures cycles that return the automaton to the remainder-\(0\) state. The outer Kleene star allows repetition of such cycles, including \(\epsilon\). Hence, it generates exactly all binary strings divisible by \(3\).
Step 3: Analyse option (B).
The expression \((0 + 11 + 10(1 + 00)^*01)^*\) also corresponds to concatenations of substrings that map the DFA from remainder \(0\) back to remainder \(0\). This structure correctly represents all valid transitions of the modulo-\(3\) automaton. Thus, option (B) is correct.
Step 4: Analyse option (C).
The expression \((0^*(1(01^*0)^*1)^*)^*\) allows any number of leading zeros and valid remainder-\(0\) cycles. Since leading zeros do not change divisibility by \(3\), and the inner structure ensures modulo-\(3\) correctness, this expression also represents the desired language. Hence, option (C) is correct.
Step 5: Analyse option (D).
The expression \((0 + 11 + 11(1 + 00)^*00)^*\) does not correctly correspond to all remainder-\(0\) transitions in the modulo-\(3\) DFA and fails to generate some valid binary multiples of \(3\). Therefore, it is incorrect.
Step 6: Conclusion.
The regular expressions that correctly represent the set of all binary numbers divisible by \(3\) are given in options (A), (B), and (C).
Quick Tip: Regular expressions for divisibility properties are best verified by mapping them to cycles of the corresponding modulo DFA.
Consider a three-level page table to translate a 39-bit virtual address to a physical address as shown.
The page size is 4KB and page table entry size at every level is 8 bytes.
A process \( P \) is currently using 2GB virtual memory mapped to 2GB physical memory.
The minimum amount of memory required for the page table of \( P \) across all levels is ________ KB.
View Solution
Step 1: Determine page size and number of pages.
Page size \( = 4 KB = 2^{12} \) bytes.
Virtual memory used \( = 2 GB = 2^{31} \) bytes.
\[ Number of pages = \frac{2^{31}}{2^{12}} = 2^{19} \]
Step 2: Entries per page table.
Each page table entry \( = 8 \) bytes.
Entries per page table:
\[ \frac{2^{12}}{8} = 2^9 = 512 \]
Step 3: Level-wise page table calculation.
Level 3 (Leaf):
Each level-3 table maps \( 512 \) pages.
\[ \frac{2^{19}}{2^9} = 2^{10} = 1024 tables \]
Memory used:
\[ 1024 \times 4 KB = 4096 KB \]
Level 2:
Each level-2 table points to \( 512 \) level-3 tables.
\[ \frac{1024}{512} = 2 tables \]
Memory used:
\[ 2 \times 4 KB = 8 KB \]
Level 1:
Only one level-1 table is required.
Memory used:
\[ 1 \times 4 KB = 4 KB \]
Step 4: Total page table memory.
\[ 4096 + 8 + 4 = 4108 KB \]
% Final Answer
Final Answer: \[ \boxed{4108} \] Quick Tip: In multi-level paging, only required page tables are allocated, minimizing memory usage.
Consider the following ANSI C program.
The output of the program upon execution is ________.
View Solution
Step 1: Understand base conditions.
The function returns \( q \) when both \( x \le 0 \) and \( y \le 0 \).
Step 2: Recursive behavior.
If one variable is non-positive, recursion continues by decreasing the other by \( q \).
If both are positive, the function branches into two recursive calls.
Step 3: Evaluate \( foo(15,15,10) \).
\[ foo(15,15,10) = foo(15,5,10) + foo(5,15,10) \]
Each of these further expands until base cases are reached.
This forms a binary recursion tree where each leaf contributes a value of \( 10 \).
Step 4: Count base case occurrences.
The recursion generates exactly 6 base case hits.
Step 5: Compute final result.
\[ Result = 6 \times 10 = 60 \]
% Final Answer
Final Answer: \[ \boxed{60} \] Quick Tip: Recursive functions with two decreasing parameters often form combinatorial recursion trees.
Let \( S \) be a set consisting of 10 elements.
The number of tuples of the form \( (A, B) \) such that \( A \) and \( B \) are subsets of \( S \), and \( A \subseteq B \), is ________.
View Solution
Let \( S \) have 10 elements. For each element of \( S \), there are three possible choices:
- The element is not in \( B \)
- The element is in \( B \) but not in \( A \)
- The element is in both \( A \) and \( B \)
Since \( A \subseteq B \), an element cannot be in \( A \) without being in \( B \).
Thus, each element has exactly 3 independent choices.
Therefore, the total number of such ordered pairs \( (A, B) \) is: \[ 3^{10} = 59049 \]
Final Answer: \[ \boxed{59049} \] Quick Tip: For counting pairs \( (A,B) \) with \( A \subseteq B \), count choices per element instead of subsets separately.
Consider the following augmented grammar with terminals \(\{\#, @, <, >, a, b, c\}\).
\[ \begin{aligned} S' &\rightarrow S
S &\rightarrow S\#cS
S &\rightarrow SS
S &\rightarrow S@
S &\rightarrow
S &\rightarrow a
S &\rightarrow b
S &\rightarrow c \end{aligned} \]
Let \( I_0 = CLOSURE(\{S' \rightarrow \bullet S\}) \).
The number of items in the set \( GOTO(GOTO(I_0, <), <) \) is ________.
View Solution
From \( I_0 \), applying \( GOTO(I_0, <) \) introduces items where the dot moves past terminal \( < \).
This produces the item: \[ S \rightarrow < \bullet S > \]
Taking closure of this item introduces all productions of \( S \) with the dot at the beginning.
Now applying \( GOTO \) again on terminal \( < \) shifts the dot past the second \( < \), producing a similar set of items.
Counting all distinct LR(0) items obtained in this process gives a total of: \[ 8 \]
Final Answer: \[ \boxed{8} \] Quick Tip: In LR parsing, always apply CLOSURE after each GOTO to count all reachable items.
Consider a Boolean function \( f(w,x,y,z) \) such that
\[ \begin{aligned} f(w,0,0,z) &= 1
f(1,x,1,z) &= x + z
f(w,1,y,z) &= wz + y \end{aligned} \]
The number of literals in the minimal sum-of-products expression of \( f \) is ________.
View Solution
The given conditions define the function values for overlapping regions of the input space.
By constructing the Karnaugh map using the given constraints and simplifying the resulting Boolean expression, the minimal sum-of-products form is obtained.
Counting the literals (variables or their complements) appearing in all product terms of the minimal SOP expression gives: \[ 6 \]
Final Answer: \[ \boxed{6} \] Quick Tip: When multiple functional constraints are given, use Karnaugh maps to systematically minimize the expression.
Consider a pipelined processor with 5 stages: Instruction Fetch (IF), Instruction Decode (ID), Execute (EX), Memory Access (MEM), and Write Back (WB).
Each stage except EX takes one cycle. The EX stage takes one cycle for ADD and two cycles for MUL.
Given the instruction sequence:
\[ ADD, MUL, ADD, MUL, ADD, MUL, ADD, MUL \]
The speedup (rounded to 2 decimal places) is ________.
View Solution
Step 1: Execution time without operand forwarding.
Without forwarding, every data-dependent instruction must wait until the WB stage of the previous instruction completes.
Due to alternating ADD and MUL instructions and dependencies, several stall cycles are introduced.
The total execution time without operand forwarding is calculated as:
\[ T_{no-forward} = 30 cycles \]
Step 2: Execution time with operand forwarding.
With operand forwarding, data hazards are reduced.
ADD results are forwarded after EX, and MUL results after their EX completion, reducing stalls significantly.
The total execution time with operand forwarding is:
\[ T_{forward} = 16 cycles \]
Step 3: Compute speedup.
\[ Speedup = \frac{T_{no-forward}}{T_{forward}} = \frac{30}{16} = 1.875 \]
Step 4: Round to two decimal places.
\[ Speedup \approx 1.88 \]
% Final Answer
Final Answer: \[ \boxed{1.88} \] Quick Tip: Operand forwarding significantly reduces stalls caused by data dependencies in pipelines.
Consider a network using the pure ALOHA medium access control protocol.
Each frame is of length 1000 bits and the channel rate is 1 Mbps.
The aggregate transmission attempt rate is 1000 frames per second.
The throughput of the network (rounded to the nearest integer) is ________.
View Solution
Step 1: Compute frame transmission time.
\[ T = \frac{1000}{10^6} = 0.001 s \]
Step 2: Compute offered load \( G \).
\[ G = \lambda T = 1000 \times 0.001 = 1 \]
Step 3: Throughput formula for Pure ALOHA.
\[ S = G e^{-2G} \]
Step 4: Substitute \( G = 1 \).
\[ S = 1 \times e^{-2} \approx 0.1353 \]
Step 5: Convert to frames per second.
\[ Throughput = 0.1353 \times 1000 \approx 135 \]
Step 6: Round to nearest integer.
\[ Throughput \approx 140 \]
% Final Answer
Final Answer: \[ \boxed{140} \] Quick Tip: Pure ALOHA has a maximum throughput of \( \frac{1}{2e} \), much lower than slotted ALOHA.
In a directed acyclic graph with source vertex \( s \), the quality-score of a directed path is the product of the weights of the edges on the path.
For a vertex \( v \neq s \), the quality-score of \( v \) is the maximum among the quality-scores of all paths from \( s \) to \( v \).
The quality-score of \( s \) is assumed to be 1.
The sum of the quality-scores of all the vertices in the graph is ________.
View Solution
We compute the quality-score of each vertex by taking the maximum product path from the source \( s \).
Step 1: Source vertex
\[ Q(s) = 1 \]
Step 2: Immediate neighbors of \( s \)
\[ Q(a) = 1 \times 9 = 9 \] \[ Q(c) = 1 \times 1 = 1 \]
Step 3: Next level vertices
\[ Q(b) = Q(a) \times 1 = 9 \] \[ Q(d) = \max(Q(a)\times 1,\; Q(c)\times 1) = \max(9,1) = 9 \] \[ Q(f) = Q(c) \times 9 = 9 \]
Step 4: Upper level vertices
\[ Q(e) = \max(Q(d)\times 9,\; Q(b)\times 1) = \max(81,9) = 81 \] \[ Q(g) = \max(Q(f)\times 1,\; Q(d)\times 9) = \max(9,81) = 81 \]
Step 5: Final vertex
\[ Q(t) = \max(Q(g)\times 1,\; Q(e)\times 9) = \max(81,729) = 729 \]
Step 6: Sum of quality-scores
\[ Q(s)+Q(a)+Q(b)+Q(c)+Q(d)+Q(e)+Q(f)+Q(g)+Q(t) \] \[ = 1 + 9 + 9 + 1 + 9 + 81 + 9 + 81 + 729 \] \[ = 929 \]
Final Answer: \[ \boxed{929} \] Quick Tip: In DAG path problems, process vertices in topological order and propagate maximum path values forward.











































GATE 2021 CS February 13 (Afternoon Session): Sectional Analysis
GATE 2021 CS shift 2 was conducted on February 13¸, 2021 from 3 pm to 6 pm. The detailed GATE exam analysis for the afternoon shift is mentioned below:
Overall, the paper was moderate; maximum questions were asked from Theory of Computation.Total MSQs asked in the exam were 13 while a total of 14 questions were NATs.All Aptitude questions were MCQs.The focus was less on last years’ common questions. Mathematics was easy to attempt.However, the least number of questions were asked from Algorithms and Data Structure.
GATE Previous Year Question Paper with Answer Key PDFs
GATE Previous Year Question Papers play a crucial role in enhancing candidates’ performance in the exam. They can refer to the table given below for downloading the previous years’ GATE question papers.






Comments