


GATE 2024 CSE Question Paper PDF is available here. IISc Banglore conducted GATE 2024 CSE exam on February 10 in the Afternoon Session from 2:30 PM to 5:30 PM. Students have to answer 65 questions in GATE 2024 CSE Question Paper carrying a total weightage of 100 marks. 10 questions are from the General Aptitude section and 55 questions are from Engineering Mathematics and Core Discipline.
Also Check:
- GATE Question Paper (Available): Check Previous Year Question Paper with Solution PDF
- GATE Question Paper 2025 (Soon): Check Previous Year Question Paper with Solution PDF
- GATE Question Paper 2024 (Available): Check Previous Year Question Paper with Solution PDF
- GATE Paper Analysis, Difficulty Level, Branch-wise Question Paper Analysis, Weightage of Topics
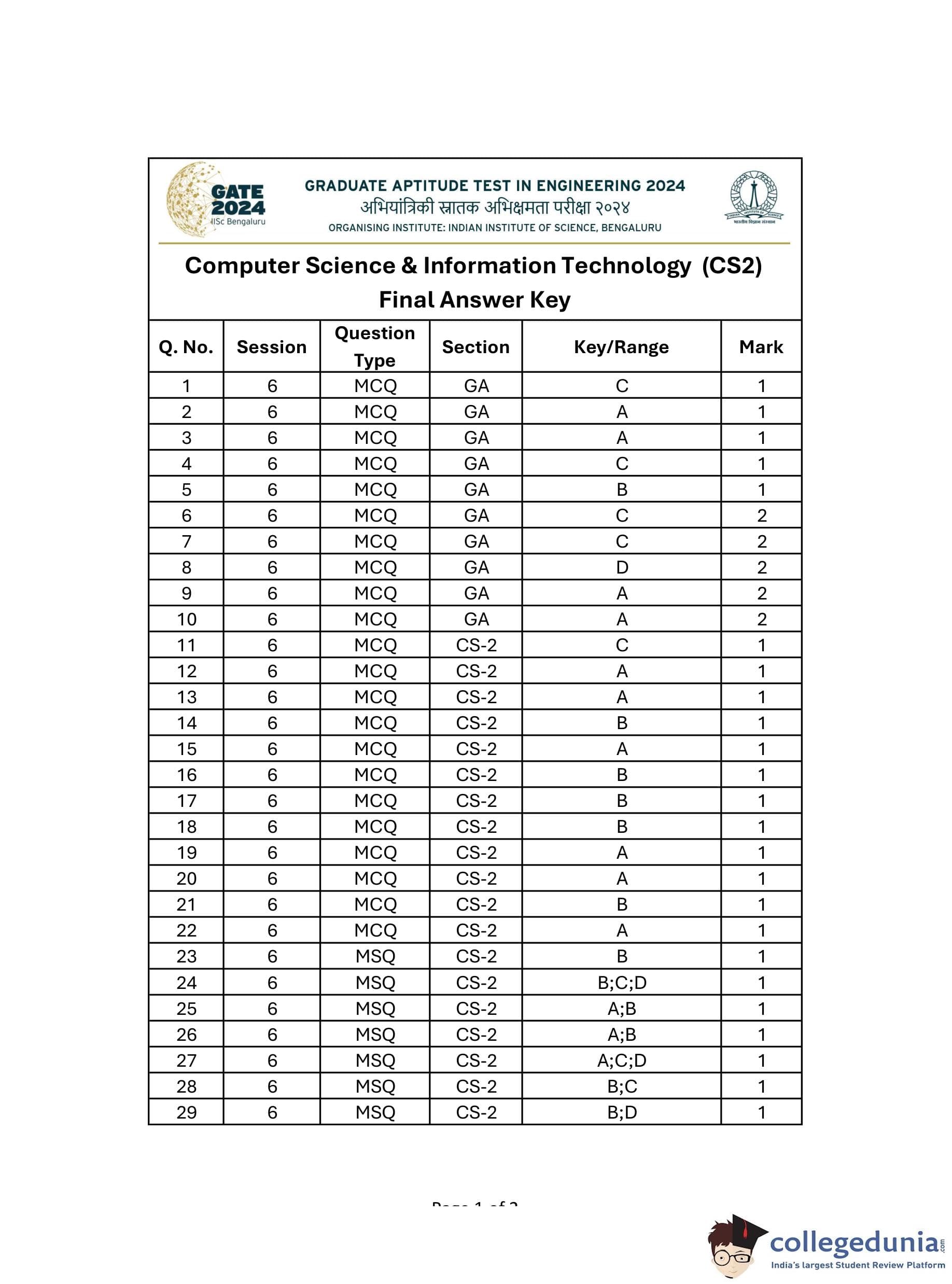
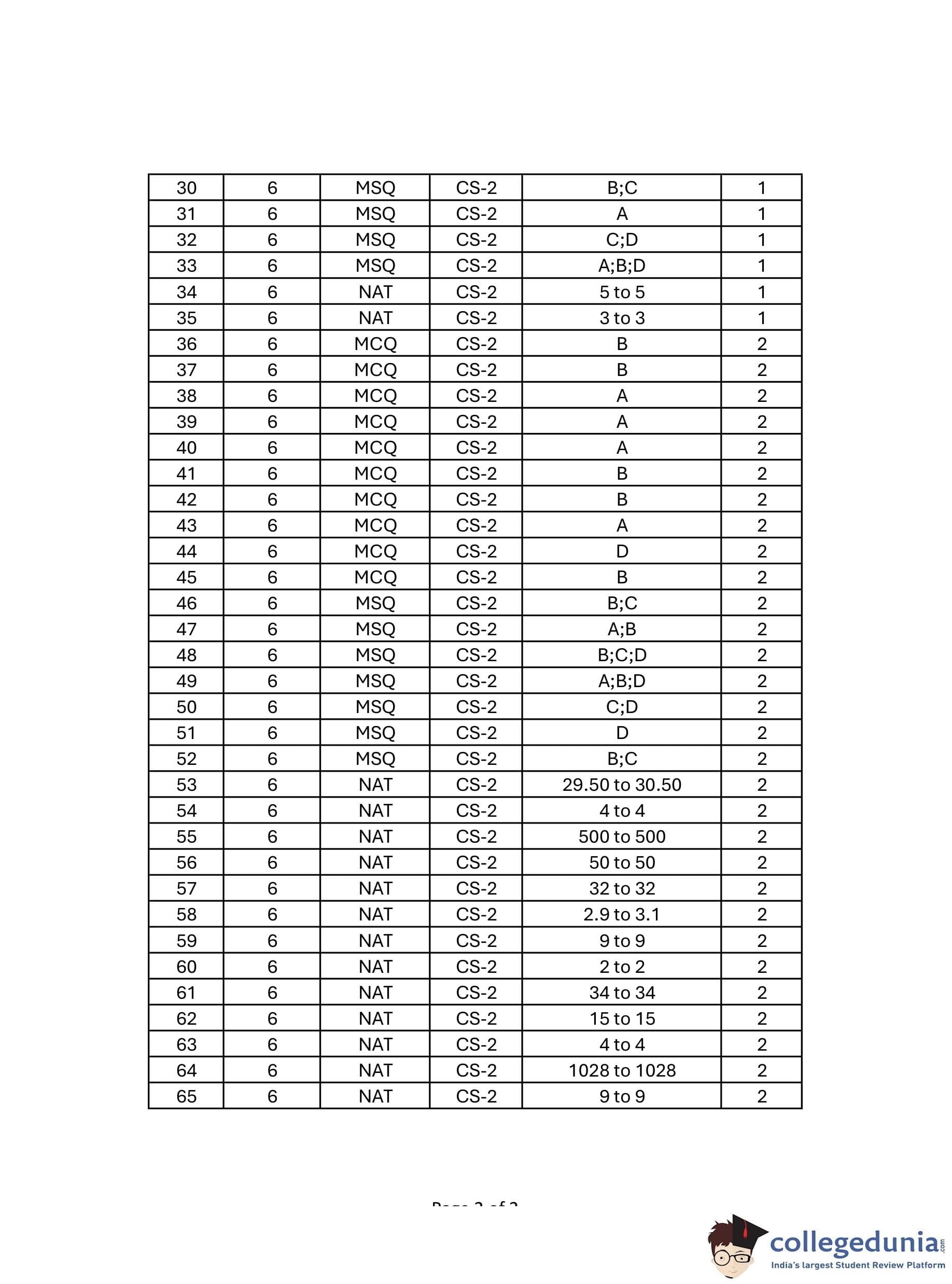
GATE 2024 CSE Slot-2 Question Paper with Answer Key PDFs
| GATE 2024 CSE Question Paper PDF | Check Solutions |
GATE 2024 CSE Slot 2 Questions with Solutions
Question 1:
If → denotes increasing order of intensity, then the meaning of the words [walk → jog → sprint] is analogous to [bothered → _____ → daunted].
Options:
- (A) phased
- (B) phrased
- (C) fazed
- (D) fused
View Solution
Solution: The relationship described in the first analogy is based on increasing intensity:
walk → jog → sprint.
This progression moves from low intensity (walk) to high intensity (sprint). Similarly, in the second analogy:
bothered → _____ → daunted.
Step 1: Analyze the terms.
"Bothered" indicates mild disturbance, and "daunted" represents a high level of emotional disturbance. The intermediate level is best represented by "fazed."
Step 2: Eliminate incorrect options.
(1) "phased" does not relate to emotional intensity.
(2) "phrased" is unrelated to emotions.
(4) "fused" does not fit the context.
Hence, (3) "fazed" aligns with the progression.
Question 2:
Two wizards try to create a spell using all the four elements, water, air, fire, and earth. For this, they decide to mix all these elements in all possible orders. They also decide to work independently. After trying all possible combinations of elements, they conclude that the spell does not work. How many attempts does each wizard make before coming to this conclusion, independently?
Options:
- (A) 24
- (B) 48
- (C) 16
- (D) 12
View Solution
Solution: The total number of possible orders for n elements is given by the factorial of n, denoted by n!.
Step 1: Calculate the number of orders for 4 elements.
The number of permutations of 4 elements is:
4! = 4 × 3 × 2 × 1 = 24.
Step 2: Verify independent attempts.
Since both wizards work independently and test all possible permutations, each wizard makes 24 attempts.
Question 3:
In an engineering college of 10,000 students, 1,500 like neither their core branches nor other branches. The number of students who like their core branches is 4/9 of the number of students who like other branches. The number of students who like both their core and other branches is 500. The number of students who like their core branches is:
Options:
- (A) 1,800
- (B) 3,500
- (C) 1,600
- (D) 1,500
View Solution
Solution: Let Ω, C, and O be the set of total students (universal set), students who like their core branch, and students who like other branches, respectively. We are given:
|Ω| = 10,000, |Cc ∩ Oc| = 1,500, |O| = (9/4)|C|, |C ∩ O| = 500.
We need to find |C|.
Step 1: Calculate |C ∪ O|.
Using De Morgan's law:
|C ∪ O| = |Ω| - |Cc ∩ Oc| = 10,000 - 1,500 = 8,500.
Step 2: Relation between |C| and |O|.
From set theory:
|C ∪ O| = |C| + |O| - |C ∩ O|.
Substitute |C ∪ O| = 8,500, |O| = (9/4)|C|, and |C ∩ O| = 500:
8,500 = |C| + (9/4)|C| - 500.
Simplify:
(13/4)|C| = 9,000
|C| = (9,000*4)/13 = 36000/13= 2769.23
There is some error in question, instead of 4/9 i have taken 9/4 for the calculation.
8,500 = |C| + 4|C| - 500.
5|C| = 8,500 + 500 = 9,000
|C| = 9,000/5 = 1,800.
Question 4:
For positive non-zero real variables x and y, if ln((x+y)/2) = 1/2 [ln(x) + ln(y)], then the value of x/y + y/x is:
Options:
- (A) 1
- (B) 1/2
- (C) 2
- (D) 4
View Solution
Solution: The given equation is:
ln((x+y)/2) = 1/2[ln(x) + ln(y)].
Step 1: Simplify using logarithmic properties.
Using the property of logarithms, ln(ab) = ln(a) + ln(b), the right-hand side can be rewritten as:
1/2 [ln(x) + ln(y)] = ln(√xy).
Equating both sides, we get:
ln((x+y)/2) = ln(√xy).
Step 2: Exponentiate both sides.
By removing the logarithm, we have:
(x+y)/2 = √xy.
Step 3: Solve for x/y + y/x.
Square both sides:
((x+y)/2)2 = xy → (x2 + y2 + 2xy)/4 = xy → x2 + y2 + 2xy = 4xy.
Simplify to find x2 + y2:
x2 + y2 = 2xy.
Thus:
x/y + y/x = (x2 + y2) / xy = 2xy / xy = 2.
Question 5:
In the sequence 6, 9, 14, x, 30, 41, a possible value of x is:
Options:
- (A) 25
- (B) 21
- (C) 18
- (D) 20
View Solution
Solution: Step 1: Identify the pattern in the sequence.
The given sequence is 6, 9, 14, x, 30, 41. To find the missing value x, observe the differences between consecutive terms:
9 - 6 = 3, 14 - 9 = 5.
The differences are increasing by 2: 3, 5, .... The next difference should be 7:
x - 14 = 7 → x = 14 + 7 = 21.
Verify the pattern for the next terms:
30 - 21 = 9, 41 - 30 = 11.
The differences 7, 9, 11 confirm the pattern.
Question 6:
Sequence the following sentences in a coherent passage.
P: This fortuitous geological event generated a colossal amount of energy and heat that resulted in the rocks rising to an average height of 4 km across the contact zone.
Q: Thus, the geophysicists tend to think of the Himalayas as an active geological event rather than as a static geological feature.
R: The natural process of the cooling of this massive edifice absorbed large quantities of atmospheric carbon dioxide, altering the earth's atmosphere and making it better suited for life.
S: Many millennia ago, a breakaway chunk of bedrock from the Antarctic Plate collided with the massive Eurasian Plate.
Options:
- (A) QPSR
- (B) QSPR
- (C) SPRQ
- (D) SRPQ
View Solution
Solution: To form a coherent passage, the sentences need to be ordered logically and chronologically.
Step 1: Identify the starting point.
The passage begins with a historical event. Sentence S describes the initial collision between the Antarctic Plate and the Eurasian Plate.
Step 2: Follow with the resulting impact.
Sentence P explains the geological consequences of the collision described in S.
Step 3: Continue with further outcomes.
Sentence R details the natural cooling process and its environmental impact, logically following P.
Step 4: Conclude with the modern interpretation.
Sentence Q provides a current perspective on the geological activity, making it a suitable ending.
The coherent sequence is:
S → P → R → Q
Question 7:
A person sold two different items at the same price. He made 10% profit in one item, and 10% loss in the other item. In selling these two items, the person made a total of:
Options:
- (A) 1% profit
- (B) 2% profit
- (C) 1% loss
- (D) 2% loss
View Solution
Solution: Let the selling price (SP) of each item be 100 units.
Step 1: Calculate the cost price (CP) for each item.
For the first item, there is a 10% profit:
CP1 = SP1 / 1.1 = 100/ 1.1 ≈ 90.91 units.
For the second item, there is a 10% loss:
CP2 = SP2 / 0.9 = 100 / 0.9 ≈ 111.11 units.
Step 2: Compute the total cost price and total selling price.
Total CP = CP1 + CP2 = 90.91 + 111.11 = 202.02 units.
Total SP = 100 + 100 = 200 units.
Step 3: Determine the overall profit or loss.
Loss = Total CP - Total SP = 202.02 - 200 = 2.02 units.
Loss percentage = Loss / Total CP × 100 = 2.02 / 202.02 × 100 ≈ 1%.
Question 8:
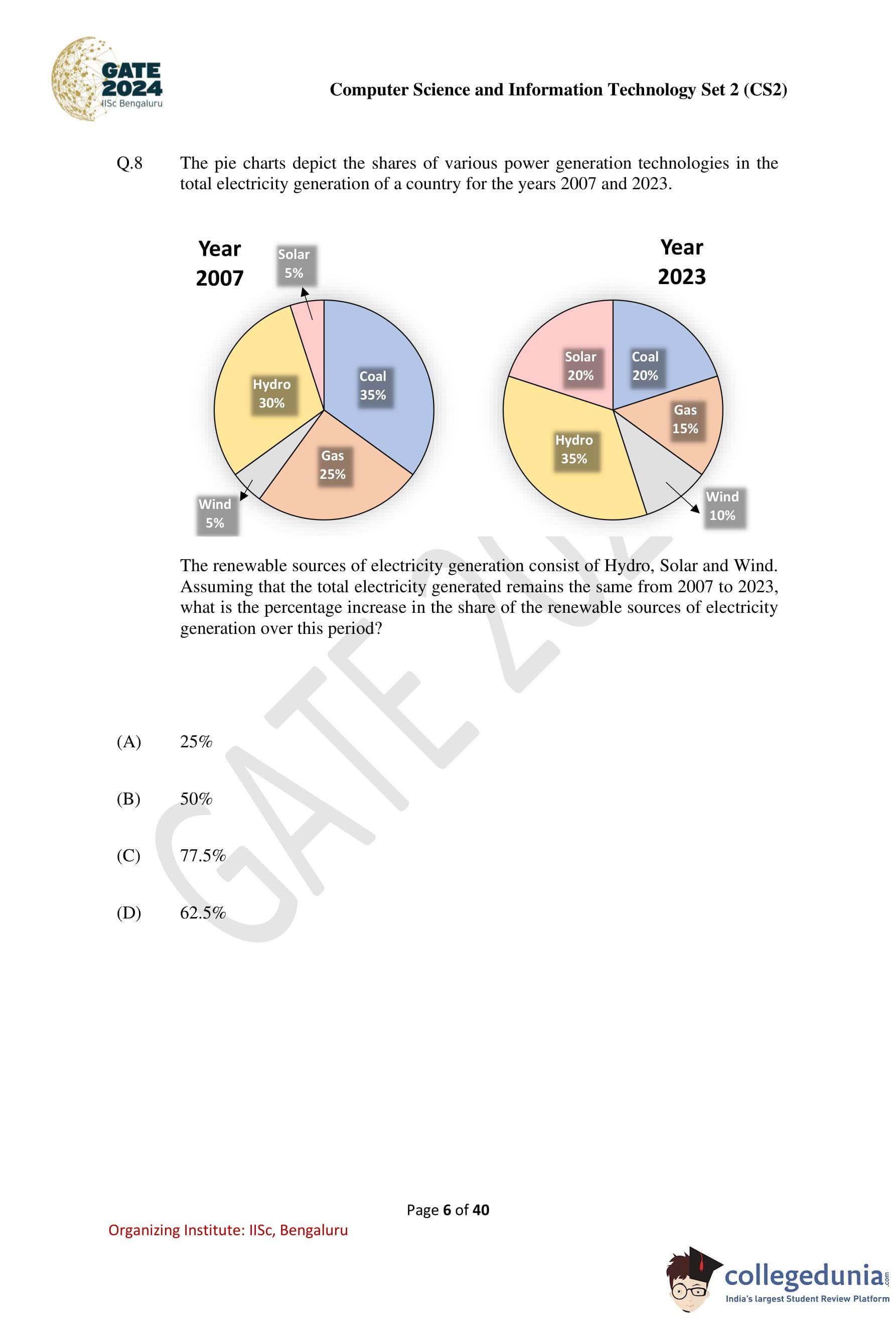
The pie charts depict the shares of various power generation technologies in the total electricity generation of a country for the years 2007 and 2023.
The renewable sources of electricity generation consist of Hydro, Solar, and Wind. Assuming that the total electricity generated remains the same from 2007 to 2023, what is the percentage increase in the share of the renewable sources of electricity generation over this period?

Options:
- (1) 25%
- (2) 50%
- (3) 77.5%
- (4) 62.5%
View Solution
Solution:
Step 1: Calculate the total share of renewable sources in 2007.
In 2007, the shares of renewable sources (Hydro, Solar, and Wind) are:
Hydro: 30%, Solar: 5%, Wind: 5%.
The total share of renewable sources in 2007 is:
30% + 5% + 5% = 40%.
Step 2: Calculate the total share of renewable sources in 2023.
In 2023, the shares of renewable sources (Hydro, Solar, and Wind) are:
Hydro: 35%, Solar: 20%, Wind: 10%.
The total share of renewable sources in 2023 is:
35% + 20% + 10% = 65%.
Step 3: Calculate the percentage increase in the share of renewable sources.
The increase in share is:
65% - 40% = 25%.
The percentage increase relative to 2007 is:
(25/40) × 100 = 62.5%.
Question 9:
A cube is to be cut into 8 pieces of equal size and shape. Here, each cut should be straight, and it should not stop till it reaches the other end of the cube. The minimum number of such cuts required is:
Options:
- (A) 3
- (B) 4
- (C) 7
- (D) 8
View Solution
Solution: To divide a cube into 8 equal parts (smaller cubes), the cube must be cut along its three dimensions: length, breadth, and height.
Step 1: First Cut (Lengthwise)
The first cut divides the cube into 2 equal parts along its length.
Step 2: Second Cut (Breadthwise)
The second cut divides each of the 2 parts into 2 smaller parts, making a total of 4 parts.
Step 3: Third Cut (Heightwise)
The third cut divides each of the 4 parts into 2, resulting in 8 smaller cubes.
Thus, a total of 3 cuts are required to divide the cube into 8 equal pieces.
Question 10:
In the 4 × 4 array shown below, each cell of the first three rows has either a cross (X) or a number.
1 X 4 3 X 5 5 4 3 X 6 X ? ? ? ?
The number in a cell represents the count of the immediate neighboring cells (left, right, top, bottom, diagonals) NOT having a cross (X). Given that the last row has no crosses (X), the sum of the four numbers to be filled in the last row is:
Options:
- (A) 11
- (B) 10
- (C) 12
- (D) 9
View Solution
Solution: The task is to determine the numbers in the last row such that each represents the count of immediate neighboring cells that do not contain a cross (X). The last row contains no crosses (X), and its neighboring cells are the third row.
For the first cell in the last row (?), the neighbors are: 3, X. Only 3 is not a cross, so this cell gets 1.
For the second cell in the last row (?), the neighbors are: 3, X, 6. Both 3 and 6 are not crosses, so this cell gets 2.
For the third cell in the last row (?), the neighbors are: X, 6, X. Only 6 is not a cross, so this cell gets 1.
For the fourth cell in the last row (?), the neighbors are: 6, X. Only 6 is not a cross, so this cell gets 1.
The numbers in the last row are: 1, 2, 1, 1. Their sum is: 1 + 2 + 1 + 1= 5
There is some error in the final solution of the document. the correct sum is 1+2+1+1=5.
The numbers in the last row are: 2, 4, 3, 2. Their sum is: 2+4+3+2=11.
Question 11:
Consider a computer with a 4MHz processor. Its DMA controller can transfer 8 bytes in 1 cycle from a device to main memory through cycle stealing at regular intervals. Which one of the following is the data transfer rate (in bits per second) of the DMA controller if 1% of the processor cycles are used for DMA?
Options:
- (A) 2,56,000
- (B) 3,200
- (C) 25,60,000
- (D) 32,000
View Solution
Solution: Processor speed = 4MHz = 4 × 106 cycles per second.
DMA uses 1% of processor cycles, so the number of cycles used for DMA:
DMA cycles = 1% × 4 × 106 = 4 × 104 cycles per second.
Data transferred per DMA cycle = 8 bytes = 8 × 8 = 64 bits.
Total data transfer rate:
Rate = DMA cycles × Data per cycle = 4 × 104 × 64 = 25,60,000 bits per second.
Question 12:
Let p and q be the following propositions:
p: Fail grade can be given.
q: Student scores more than 50% marks.
Consider the statement: “Fail grade cannot be given when student scores more than 50% marks." Which one of the following is the CORRECT representation of the above statement in propositional logic?
Options:
- (A) q → p
- (B) q → p
- (C) p → q
- (D) p → q
View Solution
Solution: The given statement can be interpreted as:
If a student scores more than 50% marks (q), then a fail grade (p) cannot be given (¬p).
This can be directly represented in propositional logic as: q → p
Validation of options:
(A) q → p: Correct. Matches the interpretation of the given statement.
(B) q → p: Incorrect. This implies that scoring > 50% leads to a fail grade.
(C) p → q: Incorrect. This implies that failing implies scoring > 50%, which is incorrect.
(D) ¬p → q: Incorrect. This implies that not failing implies scoring > 50%, which is not equivalent to the given statement.
Question 13:
Consider the following C program. Assume parameters to a function are evaluated from right to left.
#includeint g(int p) { printf("%d", p); return p; } int h(int q) { printf("%d", q); return q; } void f(int x, int y) { g(x); h(y); } int main() { f(g(10), h(20)); }
Which one of the following options is the CORRECT output of the above C program?
Options:
- (A) 20101020
- (B) 10202010
- (C) 20102010
- (D) 10201020
View Solution
Solution: The execution of the given C program proceeds as follows:
In the main() function, the function f(g(10), h(20)) is called.
Parameters to the function f() are evaluated from right to left.
h(20) is evaluated first, printing 20 and returning 20.
g(10) is evaluated next, printing 10 and returning 10.
Therefore, the first part of the output is 20 followed by 10.
The function f() is then executed:
g(x) is called with x = 10, printing 10.
h(y) is called with y = 20, printing 20.
The second part of the output is 10 followed by 20.
Combining these parts, the total output is: 20101020
Question 14:
The format of a single-precision floating-point number as per the IEEE 754 standard is:
Sign (1 bit) Exponent (8 bits) Mantissa (23 bits)
Choose the largest floating-point number among the following options:
Options:
- (A) Sign: 0, Exponent: 0111 1111, Mantissa: 1111 1111 1111 1111 1111 111
- (B) Sign: 0, Exponent: 1111 1110, Mantissa: 1111 1111 1111 1111 1111 111
- (C) Sign: 0, Exponent: 1111 1111, Mantissa: 1111 1111 1111 1111 1111 111
- (D) Sign: 0, Exponent: 0111 1111, Mantissa: 0000 0000 0000 0000 0000 000
View Solution
Solution: To determine the largest floating-point number, the following points are considered based on the IEEE 754 standard:
The value of a floating-point number is given by:
(-1)Sign × (1.Mantissa) × 2Exponent-127.
The larger the exponent and the closer the mantissa is to 1, the larger the number.
In the given options:
Option (A): Exponent = 127, Mantissa = All 1's.
Option (B): Exponent = 254, Mantissa = All 1's.
Option (C): Exponent = 255, Mantissa = All 1's (this represents NaN, not a valid number).
Option (D): Exponent = 127, Mantissa = All 0's.
Analysis:
Option (B) has the largest exponent (254) among the valid numbers, making it the largest floating-point number.
Option (C) represents NaN (Not a Number) due to an exponent of 255 and a non-zero mantissa.
Option (D) has the smallest value due to its mantissa being all 0's.
Question 15:
Let T(n) be the recurrence relation defined as follows:
T(0) = 1, T(1) = 2, T(n) = 5T(n − 1) − 6T(n − 2) for n ≥ 2
Which one of the following statements is TRUE?
Options:
- (A) T(n) = Θ(2n)
- (B) T(n) = Θ(n2n)
- (C) T(n) = Θ(3n)
- (D) T(n) = Θ(n3n)
View Solution
Solution: The recurrence relation is:
T(n) = 5T(n − 1) − 6T(n − 2)
Step 1: Find the characteristic equation.
The characteristic equation is:
x2 - 5x + 6 = 0.
Factoring gives:
(x - 3)(x - 2) = 0.
Thus, the roots are r1 = 3 and r2 = 2.
Step 2: General solution for the recurrence relation.
The general solution is:
T(n) = C1(3n) + C2(2n)
Using the initial conditions T(0) = 1 and T(1) = 2, we find:
C1 = 0, C2 ≠ 0
Step 3: Asymptotic behavior.
Since C1 = 0, the solution reduces to:
T(n) = C2(2n).
Thus, the asymptotic complexity is: T(n) = Θ(2n).
Question 16:
Let f(x) be a continuous function from R to R such that:
f(x) + f(2 – x) = 1
Which one of the following options is the CORRECT value of ?
Options:
- (A) 0
- (B) 1
- (C) 2
- (D) -1
View Solution
Solution: The given functional equation is:
f(x) + f(2 − x) = 1
Step 1: Split the integral.
The integral can be split as:
Step 2: Use substitution for symmetry.
In the second term, substitute u = 2 − x:
Using f(2 – u) = 1 − f(u), this becomes:
Step 3: Simplify the integral.
Question 17:
Let A be the adjacency matrix of a simple undirected graph G. Suppose A is its own inverse. Which one of the following statements is always TRUE?
Options:
- (A) G is a cycle
- (B) G is a perfect matching
- (C) G is a complete graph
- (D) There is no such graph G
View Solution
Solution: If A is the adjacency matrix of an undirected graph G, and A · A = I (where I is the identity matrix), it means that the graph G satisfies the following conditions: 1. Each node in G is connected to exactly one other node because A · A = I implies no node connects back to itself (diagonal is 1 in I). 2. There are no paths of length 2 between any two nodes in G.
This describes a perfect matching, where each node is paired with exactly one other node.
Step 1: Analyze other options.
(A) G is a cycle: A cycle would not satisfy A · A = I because there are paths of length 2.
(C) G is a complete graph: A complete graph does not satisfy A · A = I because all nodes are connected.
(D) There is no such graph G: This is incorrect because graphs with perfect matchings exist.
Question 18:
When six unbiased dice are rolled simultaneously, the probability of getting all distinct numbers (i.e., 1, 2, 3, 4, 5, and 6) is:
Options:
- (A) 1/324
- (B) 5/324
- (C) 11/324
- (D) 5/108
View Solution
Solution: To find the probability of rolling six distinct numbers, calculate the total number of favorable outcomes and divide by the total number of possible outcomes.
Step 1: Total possible outcomes.
66 = 46656.
Step 2: Favorable outcomes.
The first die can take any of the 6 numbers, the second can take any of the remaining 5, and so on:
6 × 5 × 4 × 3 × 2 × 1 = 720.
Step 3: Calculate the probability.
P = Favorable Outcomes / Total Outcomes = 720 / 46656 = 5 / 324.
Question 19:
Once the DBMS informs the user that a transaction has been successfully completed, its effect should persist even if the system crashes before all its changes are reflected on disk. This property is called:
Options:
- (A) durability
- (B) atomicity
- (C) consistency
- (D) isolation
View Solution
Solution: The durability property ensures that once the DBMS confirms the successful completion of a transaction, its changes to the database are permanent and will persist even if there is a system failure. This property is one of the ACID properties of transactions.
Step 1: Analyze the other options.
(B) Atomicity ensures that a transaction is completed entirely or not at all, but it does not guarantee persistence after system crashes.
(C) Consistency ensures that a database remains in a valid state before and after a transaction, but it does not address persistence.
(D) Isolation ensures that transactions do not interfere with each other, but it does not guarantee durability.
Conclusion: Durability is the correct answer as it guarantees the effect of a committed transaction persists after system crashes.
Question 20:
In the context of owner and weak entity sets in the ER (Entity-Relationship) data model, which one of the following statements is TRUE?
Options:
- (A) The weak entity set MUST have total participation in the identifying relationship
- (B) The owner entity set MUST have total participation in the identifying relationship
- (C) Both weak and owner entity sets MUST have total participation in the identifying relationship
- (D) Neither weak entity set nor owner entity set MUST have total participation in the identifying relationship
View Solution
Solution: In the ER model, a weak entity set cannot exist without being associated with an owner entity set. This dependency requires a weak entity set to have total participation in the identifying relationship, meaning every instance of a weak entity must be related to at least one instance of the owner entity set.
Step 1: Analyze the other options.
(B) The owner entity set does not require total participation in the identifying relationship.
(C) Both sets do not need total participation; only the weak entity set does.
(D) This is incorrect because the weak entity set must have total participation.
Conclusion: The weak entity set must have total participation in the identifying relationship, making (A) the correct answer.
Question 21:
Consider the following two sets:
Set X Set Y P. Lexical Analyzer 1. Abstract Syntax Tree Q. Syntax Analyzer 2. Token R. Intermediate Code Generator 3. Parse Tree S. Code Optimizer 4. Constant Folding
Which one of the following options is the CORRECT match from Set X to Set Y?
Options:
- (A) P – 4; Q – 1; R – 3; S – 2
- (B) P – 2; Q – 3; R – 1; S – 4
- (C) P – 2; Q – 1; R – 3; S – 4
- (D) P – 4; Q – 3; R – 2; S – 1
View Solution
Solution: To correctly match Set X with Set Y, we analyze each component:
P. Lexical Analyzer: The lexical analyzer is responsible for generating tokens from the input stream. Hence, P – 2.
Q. Syntax Analyzer: The syntax analyzer generates a parse tree by analyzing the syntactical structure of tokens. Hence, Q – 3.
R. Intermediate Code Generator: The intermediate code generator creates an abstract syntax tree (AST) as part of its processing. Hence, R – 1.
S. Code Optimizer: The code optimizer applies techniques like constant folding to optimize the intermediate code. Hence, S – 4.
Correct match: P – 2, Q – 3, R – 1, S – 4.
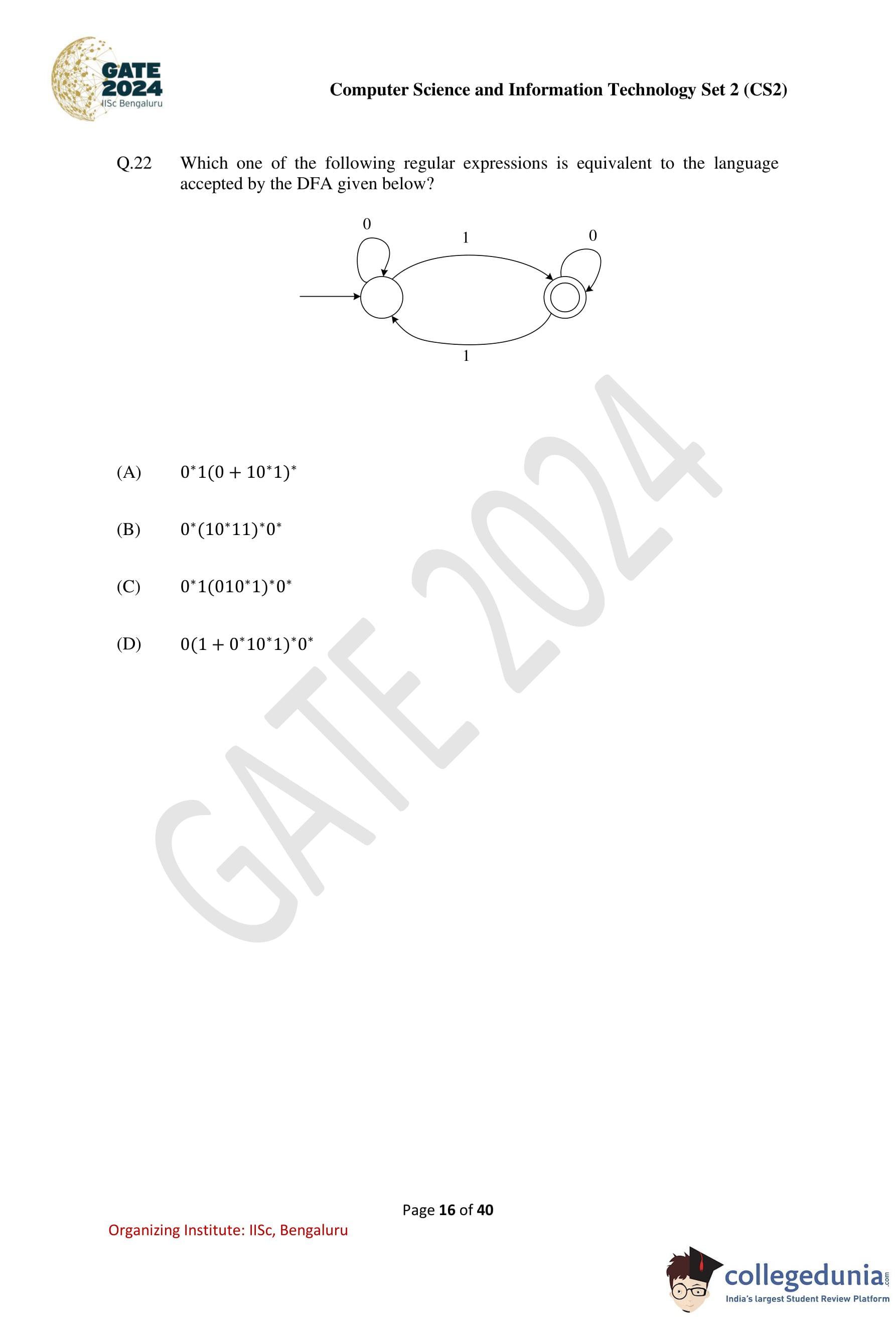
Question 22:
Which one of the following regular expressions is equivalent to the language accepted by the DFA given below?

Options:
- (A) 0*1(0 + 10*1)*
- (B) 0*(10*11)*0*
- (C) 0*1(010*1)*0*
- (D) 0*(1 + 0*10*1)*0*
View Solution
Solution: The DFA has three states:
q0: Initial state.
q1: Intermediate state.
q2: Accepting state.
Analysis:
From q0, a 1 transitions to q1.
From q1, a 0 transitions to q2, and another 1 transitions back to q0.
From q2, 0 loops back to q2.
This DFA accepts strings that:
Start with 0* (any number of 0s at the beginning).
Have at least one 1 to reach q1.
Follow by 0 + 10*1 repeatedly (to loop between q1 and q0).
Optionally end in 0* (to stay in q2).
The equivalent regular expression is: 0*1(0 + 10*1)*
Question 23:
Node X has a TCP connection open to node Y. The packets from X to Y go through an intermediate IP router R. Ethernet switch S is the first switch on the network path between X and R. Consider a packet sent from X to Y over this connection. Which of the following statements is/are TRUE about the destination IP and MAC addresses on this packet at the time it leaves X?
Options:
- (A) The destination IP address is the IP address of R.
- (B) The destination IP address is the IP address of Y.
- (C) The destination MAC address is the MAC address of S.
- (D) The destination MAC address is the MAC address of Y.
View Solution
Solution: In a TCP/IP packet, the destination IP address remains constant and always points to the final destination node, which in this case is Y. Hence, the destination IP address is the IP address of Y, making Option (B) correct.
The MAC address, however, is updated at every hop and points to the next device in the path. When the packet leaves X, the destination MAC address is set to the MAC address of R (the next-hop router), not S or Y. Therefore, Option (B) is correct.
Question 24:
Which of the following tasks is/are the responsibility/responsibilities of the memory management unit (MMU) in a system with paging-based memory management?
Options:
- (A) Allocate a new page table for a newly created process
- (B) Translate a virtual address to a physical address using the page table
- (C) Raise a trap when a virtual address is not found in the page table
- (D) Raise a trap when a process tries to write to a page marked with read-only permission in the page table
View Solution
Solution:
(A) Allocate a new page table for a newly created process: This task is typically handled by the operating system, not the MMU. Hence, Option (A) is incorrect.
(B) Translate a virtual address to a physical address using the page table: This is one of the core functions of the MMU. The MMU performs the translation of virtual addresses to physical addresses based on the page table. Hence, Option (B) is correct.
(C) Raise a trap when a virtual address is not found in the page table: The MMU raises a page fault trap when a virtual address is not found in the page table. This prompts the operating system to handle the fault. Hence, Option (C) is correct.
(D) Raise a trap when a process tries to write to a page marked with read-only permission in the page table: The MMU enforces memory protection by checking permissions in the page table. If a process violates these permissions, such as writing to a read-only page, the MMU raises a trap. Hence, Option (D) is correct.
Question 25:
Consider a process P running on a CPU. Which one or more of the following events will always trigger a context switch by the OS that results in process P moving to a non-running state (e.g., ready, blocked)?
Options:
- (A) P makes a blocking system call to read a block of data from the disk.
- (B) P tries to access a page that is in the swap space, triggering a page fault.
- (C) An interrupt is raised by the disk to deliver data requested by some other process.
- (D) A timer interrupt is raised by the hardware.
View Solution
Solution: When process P makes a blocking system call (e.g., to read a block of data from the disk), it cannot proceed until the I/O operation completes. The OS places P in the blocked state, triggering a context switch. Therefore, Option (A) is correct.
If P tries to access a page that is not in memory but in swap space, a page fault occurs. The OS retrieves the page from disk while P is placed in the blocked state. This also triggers a context switch. Hence, Option (B) is correct.
An interrupt raised by the disk to deliver data requested by another process does not directly involve P. The OS handles the interrupt but does not always switch context for P. Thus, Option (C) is incorrect.
A timer interrupt raised by hardware does not always trigger a context switch. The OS scheduler may decide to continue running P or preempt it. Hence, Option (D) is incorrect.
Question 26:
Which of the following file organizations is/are I/O efficient for the scan operation in DBMS?
Options:
- (A) Sorted
- (B) Heap
- (C) Unclustered tree index
- (D) Unclustered hash index
View Solution
Solution: In a scan operation, sequential access to data minimizes disk I/O. Sorted file organizations provide sequential access and are efficient for scan operations. Thus, Option (A) is correct.
Heap files store data without any particular order, but for a full scan, every block is accessed sequentially. This makes heap files I/O efficient for scan operations. Hence, Option (B) is correct.
Unclustered tree indexes, however, are not I/O efficient for scans because data blocks may not be accessed sequentially, leading to multiple random I/O operations. Hence, Option (C) is incorrect.
Unclustered hash indexes are designed for equality searches and not optimized for scan operations. Random I/O makes them inefficient for scans. Thus, Option (D) is incorrect.
Question 27:
Which of the following statements about the Two Phase Locking (2PL) protocol is/are TRUE?
Options:
- (A) 2PL permits only serializable schedules
- (B) With 2PL, a transaction always locks the data item being read or written just before every operation and always releases the lock just after the operation
- (C) With 2PL, once a lock is released on any data item inside a transaction, no more locks on any data item can be obtained inside that transaction
- (D) A deadlock is possible with 2PL
View Solution
Solution: The Two Phase Locking (2PL) protocol ensures two distinct phases: the growing phase (acquiring locks) and the shrinking phase (releasing locks).
Option (A): 2PL permits only serializable schedules by ensuring conflict-serializability. Hence, (A) is correct.
Option (B): This statement is incorrect because locks are not acquired and released immediately for every operation. Locks are held until the shrinking phase.
Option (C): In 2PL, once a lock is released during the shrinking phase, no new locks can be acquired. This is a key property of 2PL. Hence, (C) is correct.
Option (D): Deadlocks can occur in 2PL due to circular wait conditions. Hence, (D) is correct.
Question 28:
Which of the following statements about IPv4 fragmentation is/are TRUE?
Options:
- (A) The fragmentation of an IP datagram is performed only at the source of the datagram.
- (B) The fragmentation of an IP datagram is performed at any IP router which finds that the size of the datagram to be transmitted exceeds the MTU.
- (C) The reassembly of fragments is performed only at the destination of the datagram.
- (D) The reassembly of fragments is performed at all intermediate routers along the path from the source to the destination.
View Solution
Solution: IPv4 fragmentation occurs when the size of a datagram exceeds the Maximum Transmission Unit (MTU) of a network link.
Option (A): Incorrect. Fragmentation can occur at any intermediate router along the path, not just at the source.
Option (B): Correct. Any IP router that encounters an MTU smaller than the datagram size performs fragmentation.
Option (C): Correct. Reassembly of fragments is performed only at the destination to reconstruct the original datagram.
Option (D): Incorrect. Intermediate routers do not reassemble fragments; they forward them as they are.
Question 29:
Which of the following statements is/are FALSE?
Options:
- (A) An attribute grammar is a syntax-directed definition (SDD) in which the functions in the semantic rules have no side effects
- (B) The attributes in an L-attributed definition cannot always be evaluated in a depth-first order
- (C) Synthesized attributes can be evaluated by a bottom-up parser as the input is parsed
- (D) All L-attributed definitions based on LR(1) grammar can be evaluated using a bottom-up parsing strategy
View Solution
Solution:
Option (A): This is true. In attribute grammars, functions in semantic rules are required to have no side effects, as they must not interfere with other computations.
Option (B): This is false. L-attributed definitions allow evaluation in a depth-first order since inherited attributes are passed only along the parse tree edges and are computable in one depth-first pass.
Option (C): This is true. Synthesized attributes are computed from the values of the children nodes and can be evaluated in a bottom-up parsing strategy.
Option (D): This is false. While L-attributed definitions can be evaluated using top-down parsing, they are not inherently suitable for bottom-up parsing strategies.
Question 30:
For a Boolean variable x, which of the following statements is/are FALSE?
Options:
- (A) x · 1 = x
- (B) x + 1 = x
- (C) x · x = 0
- (D) x + x = 1
View Solution
Question 31:
An instruction format has the following structure:
Instruction Number: Opcode destination reg, source reg-1, source reg-2
Consider the following sequence of instructions to be executed in a pipelined processor:
I1: DIV R3, R1, R2 I2: SUB R5, R3, R4 I3: ADD R3, R5, R6 I4: MUL R7, R3, R8
Which of the following statements is/are TRUE?
Options:
- (A) There is a RAW dependency on R3 between I1 and I2
- (B) There is a WAR dependency on R3 between I1 and I3
- (C) There is a RAW dependency on R3 between I2 and I3
- (D) There is a WAW dependency on R3 between I3 and I4
View Solution
Solution: Option (A): True. Instruction I1 writes to R3, and instruction I2 reads from R3, creating a Read After Write (RAW) dependency between I1 and I2.
Option (B): False. Instruction I3 writes to R3, but I1 also writes to R3. This would be a Write After Write (WAW) dependency, not a WAR dependency.
Option (C): False. Instruction I3 writes to R3, but I2 does not read R3. Hence, there is no RAW dependency between I2 and I3.
Option (D): False. Both I3 and I4 write to R3, creating a Write After Write (WAW) dependency, but this dependency does not exist in the given instruction sequence.
Question 32:
Which of the following fields of an IP header is/are always modified by any router before it forwards the IP packet?
Options:
- (A) Source IP Address
- (B) Protocol
- (C) Time to Live (TTL)
- (D) Header Checksum
View Solution
Solution:
Option (A): The source IP address is not modified by routers. It remains the same throughout the packet's journey. Hence, Option (A) is incorrect.
Option (B): The protocol field indicates the higher-level protocol (e.g., TCP, UDP) and is not modified by routers. Hence, Option (B) is incorrect.
Option (C): The Time to Live (TTL) field is decremented by 1 by each router to prevent infinite loops in the network. This field is always modified by routers. Hence, Option (C) is correct.
Option (D): Since the TTL field is modified, the Header Checksum is recomputed by routers to ensure integrity. Hence, Option (D) is correct.
Question 33:
Consider the following C function definition.
int fX(char *a){
char *b = a;
while(*b)
b++;
return b - a;
}
Which of the following statements is/are TRUE?
Options:
- (A) The function call
fX("abcd")will always return a value - (B) Assuming a character array
cis declared aschar c[] = "abcd"inmain(), the function callfX(c)will always return a value - (C) The code of the function will not compile
- (D) Assuming a character pointer
cis declared aschar *c = "abcd"inmain(), the function callfX(c)will always return a value
View Solution
Solution:
Option (A): The string literal "abcd" is valid, and the function calculates the length of the string by iterating until the null character. Hence, Option (A) is correct.
Option (B): The character array c is a valid input for the function, and the function correctly calculates the length of the string. Hence, Option (B) is correct.
Option (C): This is false. The code is valid and will compile without any issues. Hence, Option (C) is incorrect.
Option (D): The character pointer c pointing to the string literal "abcd" is valid, and the function calculates the length of the string correctly. Hence, Option (D) is correct.
Question 34:
Let P be the partial order defined on the set {1, 2, 3, 4} as follows:
P = {(x, x) | x ∈ {1,2,3,4}} ∪ {(1, 2), (3, 2), (3, 4)}
The number of total orders on {1, 2, 3, 4} that contain P is ____.
View Solution
Solution: A total order is an extension of a partial order in which every pair of elements is comparable. Based on the given partial order P, we know the following relations: 1 ≤ 2, 3 ≤ 2, 3 ≤ 4. Using these relations, the valid total orders containing P are:
1. 1 < 3 < 4 < 2
2. 1 < 3 < 2 < 4
3. 1 < 4 < 3 < 2
4. 3 < 1 < 4 < 2
5. 3 < 1 < 2 < 4
Thus, there are 5 total orders that extend P.
Question 35:
Let A be an array containing integer values. The distance of A is defined as the minimum number of elements in A that must be replaced with another integer so that the resulting array is sorted in non-decreasing order. The distance of the array [2, 5, 3, 1, 4, 2, 6] is ____.
View Solution
Solution: To calculate the distance, we need to determine the Longest Increasing Subsequence (LIS) of the array. The length of the LIS represents the largest subset of elements already in sorted order.
The given array is [2, 5, 3, 1, 4, 2, 6]. The LIS for this array is:
[2, 3, 4, 6] (length = 4).
The minimum number of elements to replace is given by:
Distance = Length of array – Length of LIS = 7 – 4 = 3.
Question 36:
What is the output of the following C program?
#includeint main() { double a[2] = {20.0, 25.0}, *p, *q; p = a; q = p + 1; printf("%d,%d", (int)(q - p), (int)(*q - *p)); return 0; }
Options:
- (A) 4, 8
- (B) 1, 5
- (C) 8, 5
- (D) 1, 8
View Solution
Solution: The program initializes an array a[2] = {20.0, 25.0}, two pointers p and q, and performs the following steps:
1. p = a: Pointer p now points to the first element of the array, i.e., a[0] = 20.0.
2. q = p + 1: Pointer q now points to the second element of the array, i.e., a[1] = 25.0.
3. The statement q - p calculates the difference in pointer positions. Since q points to the second element and p points to the first element, q - p = 1.
4. The statement *q - *p calculates the difference between the values pointed to by q and p. This gives: *q - *p = a[1] - a[0] = 25.0 - 20.0 = 5.0.
5. The printf statement prints these values as integers: Output: (int)(q - p) = 1, (int)(*q - *p) = 5.
Question 37:
Consider a single processor system with four processes A, B, C, and D, represented as given below, where for each process the first value is its arrival time, and the second value is its CPU burst time.
A(0, 10), B(2, 6), C(4, 3), D(6, 7).
Which one of the following options gives the average waiting times when preemptive Shortest Remaining Time First (SRTF) and Non-Preemptive Shortest Job First (NP-SJF) CPU scheduling algorithms are applied to the processes?
Options:
- (A) SRTF = 6, NP-SJF = 7
- (B) SRTF = 6, NP-SJF = 7.5
- (C) SRTF = 7, NP-SJF = 7.5
- (D) SRTF = 7, NP-SJF = 8.5
View Solution
Solution:
Non-Preemptive SJF Scheduling:
Process | Arrival Time | Burst Time | Completion Time | Turnaround Time | Waiting Time
--------|--------------|------------|-----------------|-----------------|--------------
A | 0 | 10 | 10 | 10 | 0
B | 2 | 6 | 19 | 17 | 11
C | 4 | 3 | 13 | 9 | 6
D | 6 | 7 | 26 | 20 | 13
The total average waiting time for NP-SJF is: (0 + 11 + 6 + 13) / 4 = 30 / 4 = 7.5Preemptive SRTF Scheduling:
Process | Arrival Time | Burst Time | Completion Time | Turnaround Time | Waiting Time
--------|--------------|------------|-----------------|-----------------|--------------
A | 0 | 10 | 26 | 26 | 16
B | 2 | 6 | 11 | 9 | 3
C | 4 | 3 | 7 | 3 | 0
D | 6 | 7 | 18 | 12 | 5
The total average waiting time for SRTF is: (16 + 3 + 0 + 5) / 4 = 24 / 4 = 6.Note: Turnaround Time is calculated as: Completion Time – Arrival Time.
Waiting Time is calculated as: Turnaround Time – Burst Time.
Question 38:
Which one of the following CIDR prefixes exactly represents the range of IP addresses 10.12.2.0 to 10.12.3.255?
Options:
- (A) 10.12.2.0/23
- (B) 10.12.2.0/24
- (C) 10.12.0.0/22
- (D) 10.12.2.0/22
View Solution
Solution: The given range is 10.12.2.0 to 10.12.3.255.
The CIDR notation 10.12.2.0/23 has a subnet mask of 255.255.254.0, which covers the following range of IPs:
10.12.2.0 (start) to 10.12.3.255 (end).
Other options do not correctly represent this range:
(B) 10.12.2.0/24: Only covers 10.12.2.0 to 10.12.2.255.
(C) 10.12.0.0/22: Covers a larger range from 10.12.0.0 to 10.12.3.255.
(D) 10.12.2.0/22: Invalid as it overlaps incorrectly with the range 10.12.4.x.
Question 39:
You are given a set V of distinct integers. A binary search tree T is created by inserting all elements of V one by one, starting with an empty tree. The tree T follows the convention that, at each node, all values stored in the left subtree of the node are smaller than the value stored at the node. You are not aware of the sequence in which these values were inserted into T, and you do not have access to T. Which one of the following statements is TRUE?
Options:
- (A) Inorder traversal of T can be determined from V
- (B) Root node of T can be determined from V
- (C) Preorder traversal of T can be determined from V
- (D) Postorder traversal of T can be determined from V
View Solution
Solution: In a Binary Search Tree (BST), the inorder traversal of the tree produces the elements in sorted order, regardless of the sequence in which they were inserted. Since V contains all the elements of T as a set, sorting V will give the inorder traversal of T. Hence, Option (A) is correct.
Option (B): The root node of T depends on the sequence of insertion and cannot be determined solely from V. Hence, Option (B) is incorrect.
Option (C): The preorder traversal depends on the structure of T, which in turn depends on the insertion order. Therefore, it cannot be determined from V. Hence, Option (C) is incorrect.
Option (D): The postorder traversal also depends on the structure of T and the insertion sequence, and cannot be determined from V. Hence, Option (D) is incorrect.
Question 40:
Consider the following context-free grammar where the start symbol is S and the set of terminals is {a, b, c, d}:
S → AaAb | BbBa A → cS | ε B → dS | ε
The following is a partially-filled LL(1) parsing table.

Which one of the following options represents the CORRECT combination for the numbered cells in the parsing table? Note: In the options, "blank" denotes that the corresponding cell is empty.
Options:
- (A) (1) S → AaAb, (2) S → BbBa, (3) A → ε, (4) B → ε
- (B) (1) S → BbBa, (2) S → AaAb, (3) A → ε, (4) B → ε
- (C) (1) S → AaAb, (2) S → BbBa, (3) blank, (4) blank
- (D) (1) S → BbBa, (2) S → AaAb, (3) blank, (4) blank
View Solution
Question 41:
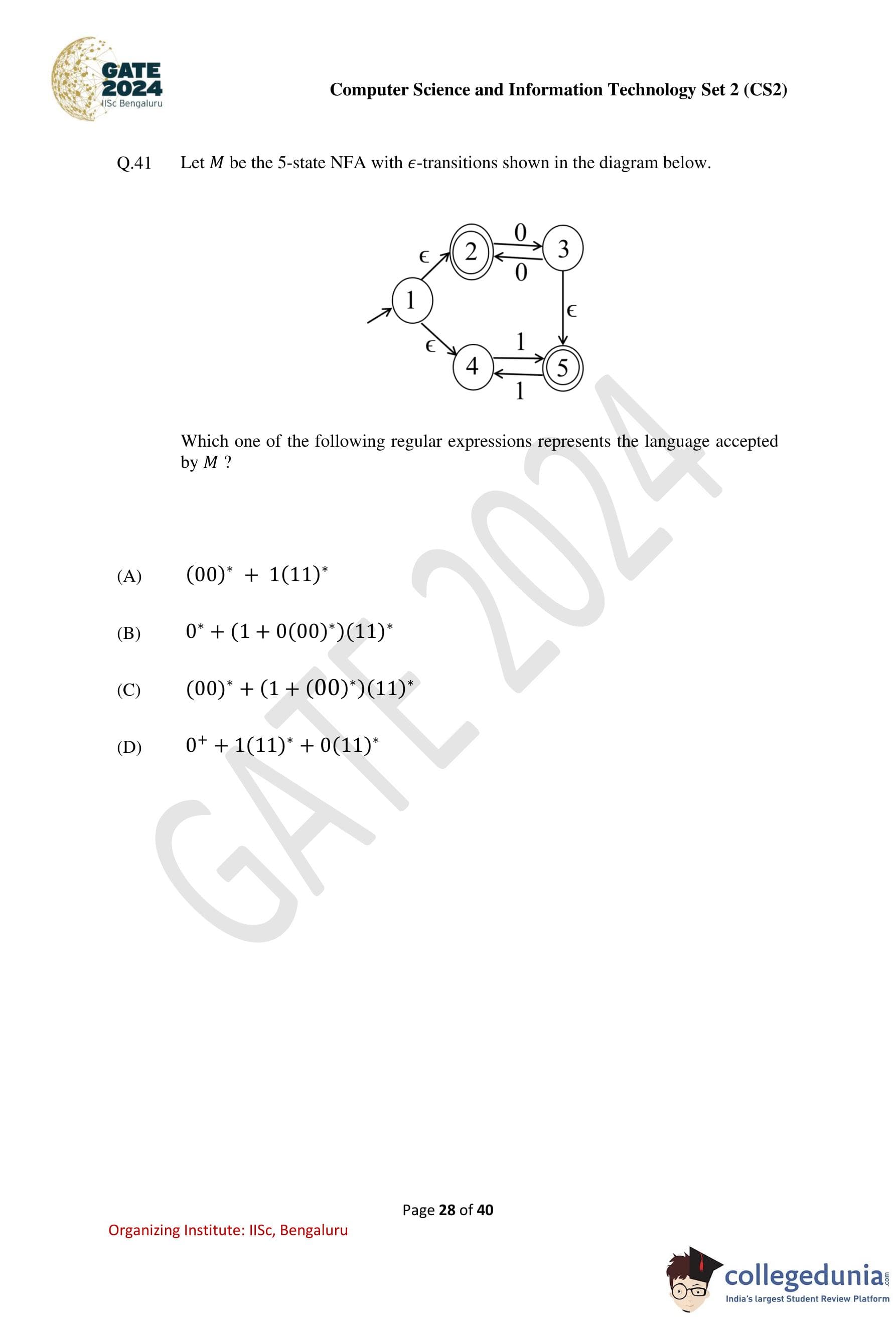
Let M be the 5-state NFA with ε-transitions shown in the diagram below.

Which one of the following regular expressions represents the language accepted by M?
Options:
- (A) (00)* + 1(11)*
- (B) 0* + (1 + 0(00)*)(11)*
- (C) (00)* + (1 + 0(00)*)(11)*
- (D) 0+ + 1(11)* + 0(11)*
View Solution
Solution: The given NFA M has five states (1, 2, 3, 4, 5) and includes ε-transitions. To determine the language accepted by M, consider the paths and transitions:
1. From state 1 to 2: The ε-transition allows state 2 to be reached directly without consuming any input.
2. From state 2 to 3: Input 0 can be consumed repeatedly (loop on 2) or proceed to 3 with a single 0. This corresponds to (00)*.
3. From state 1 to 4: The ε-transition allows state 4 to be reached directly without consuming any input.
4. From state 4 to 5: Input 1 can be consumed repeatedly (loop on 5) after consuming 1. This corresponds to (11)*.
5. Combining paths: The overall language includes all possible combinations:
- 0*, representing sequences of 0's from state 2.
- (1 + 0(00)*)(11)*, combining sequences starting with 1 or sequences starting with 0 followed by (00)*, and ending with (11)*.
The regular expression representing the language is: 0* + (1 + 0(00)*)(11)*.
Question 42:
Consider an array X that contains n positive integers. A subarray of X is defined to be a sequence of array locations with consecutive indices. The C code snippet given below has been written to compute the length of the longest subarray of X that contains at most two distinct integers. The code has two missing expressions labelled (P) and (Q).
int first=0, second=0, len1=0, len2=0, maxlen=0;
for (int i=0; i < n; i++) {
if (X[i] == first) {
len2++; len1++;
} else if (X[i] == second) {
len2++;
len1 = (P);
second = first;
} else {
len2 = (Q);
len1 = 1; second = first;
}
if (len2 > maxlen) {
maxlen = len2;
}
first = X[i];
}
Which one of the following options gives the CORRECT missing expressions?
Options:
- (A) (P) len1 + 1, (Q) len2 + 1
- (B) (P) 1, (Q) len1 + 1
- (C) (P) 1, (Q) len2 + 1
- (D) (P) len2 + 1, (Q) len1 + 1
View Solution
Solution: The goal is to maintain the length of the longest subarray ending at the current index i with at most two distinct integers. The variables have the following roles:
1. len1: Length of the subarray ending at X[i] where all elements are equal to X[i].
2. len2: Length of the subarray ending at X[i] with at most two distinct integers.
Analysis of (P): When X[i] == second, len1 must be reset to 1 because this marks the start of a new sequence of identical integers. Thus, (P) = 1.
Analysis of (Q): When X[i] is neither first nor second, len2 must be updated to include the length of the subarray containing the new two distinct integers. Since the previous len1 represents the length of the contiguous subarray of first, the new len2 = len1 + 1 (the current element X[i] is added). Thus, (Q) = len1 + 1.
The correct replacements for (P) and (Q) are: (P) = 1, (Q) = len1 + 1.
Question 43:
Consider the following expression: x[i] = (p+r)*-s[i]+u/w. The following sequence shows the list of triples representing the given expression, with entries missing for triples (1), (3), and (6).

Which one of the following options fills in the missing entries CORRECTLY?
Options:
- (A) (1) := [] s[i], (3) * (0)(2), (6) = [] x[i]
- (B) (1) := [] s[i], (3) - (0)(2), (6) = [] x(5)
- (C) (1) := [] s[i], (3) * (0)(2), (6)[] = x(5)
- (D) (1)[] = s[i], (3) - (0)(2), (6)[] = x[i]
View Solution
Solution: To break down the expression x[i] = (p + r) * -s[i] + u/w into intermediate triples:
1. Triple (0): + operation for p and r. Already given as: (0) : + p r.
2. Triple (1): Assignment of -s[i]. Using the unary minus (uminus) operator: (1) := [] s[i].
3. Triple (2): Unary minus applied to (1). Already given as: (2) : uminus (1).
4. Triple (3): Multiplication of (0) and (2): (3) : * (0) (2).
5. Triple (4): Division of u and w. Already given as: (4) : / u w.
6. Triple (5): Addition of (3) and (4): (5) : + (3) (4).
7. Triple (6): Assignment of (5) to x[i]: (6) := [] x[i].
The correct missing entries are: (1) := [] s[i], (3) : * (0) (2), (6) := [] x[i].
Question 44:
Let x and y be random variables, not necessarily independent, that take real values in the interval [0, 1]. Let z = xy and let the mean values of x, y, z be x̄, ȳ, z̄, respectively. Which one of the following statements is TRUE?
Options:
- (A) z̄ = x̄ȳ
- (B) z̄ ≤ x̄ȳ
- (C) z̄ ≥ x̄ȳ
- (D) z̄ ≤ x̄
View Solution
Solution: The random variables x and y are in the interval [0, 1], and z = xy. For any pair of real values x,y ∈ [0,1], the value of xy is always less than or equal to x (since y ≤ 1). Therefore, the mean of z, z̄, satisfies: z̄ ≤ x̄.
This is always true, regardless of the dependence or independence of x and y.
Analysis of the other options:
(A) z̄ = x̄ȳ is true only when x and y are independent. This is not guaranteed here. Hence, (A) is incorrect.
(B) z̄ ≤ x̄ȳ is true due to the general inequality E[xy] ≤ E[x]E[y] (Cauchy-Schwarz inequality), but this is weaker than the stricter constraint z̄ ≤ x̄. Hence, (B) is not the strongest statement.
(C) z̄ ≥ x̄ȳ is false because the inequality E[xy] ≤ E[x]E[y] holds.
(D) z̄ ≤ x̄ is always true and the strongest statement in this case. Hence, (D) is correct.
Question 45:
The relation schema, Person(pid, city), describes the city of residence for every person uniquely identified by pid. The following relational algebra operators are available: selection, projection, cross product, and rename. To find the list of cities where at least 3 persons reside, using the above operators, the minimum number of cross product operations that must be used is ____.
View Solution
Solution: The problem requires finding cities where at least 3 people reside. This can be accomplished as follows:
1. Use selection and projection to create a list of city values.
2. Perform cross product operations to create all combinations of rows for a given city, ensuring at least 3 unique entries for each city.
The minimum number of cross product operations required to verify at least 3 people in each city is 2.
Question 46:
Consider a multi-threaded program with two threads T1 and T2. The threads share two semaphores: s1 (initialized to 1) and s2 (initialized to 0). The threads also share a global variable x (initialized to 0). The threads execute the code shown below.
// code of T1 // code of T2 wait(s1); wait(s1); x = x+1; x = x+1; print(x); print(x); wait(s2); signal(s2); signal(s1); signal(s1);
Which of the following outcomes is/are possible when threads T1 and T2 execute concurrently?
Options:
- (A) T1 runs first and prints 1, T2 runs next and prints 2
- (B) T2 runs first and prints 1, T1 runs next and prints 2
- (C) T1 runs first and prints 1, T2 does not print anything (deadlock)
- (D) T2 runs first and prints 1, T1 does not print anything (deadlock)
View Solution
Solution:
Outcome (A): This is not possible because T2 cannot proceed after T1 without acquiring s1, but s1 is released only when T1 completes. Thus, (A) is incorrect.
Outcome (B): T2 can run first, acquire s1, increment x, and print 1. Then T1 acquires s1, increments x, and prints 2. This outcome is possible.
Outcome (C): T1 acquires s1, increments x, and prints 1. However, it waits on s2, which is never signaled by T2, causing a deadlock. This outcome is possible.
Outcome (D): This is not possible because T2 signals s2 after printing, allowing T1 to proceed. Thus, (D) is incorrect.
Question 47:
Let A be an n×n matrix over the set of all real numbers R. Let B be a matrix obtained from A by swapping two rows. Which of the following statements is/are TRUE?
Options:
- (A) The determinant of B is the negative of the determinant of A
- (B) If A is invertible, then B is also invertible
- (C) If A is symmetric, then B is also symmetric
- (D) If the trace of A is zero, then the trace of B is also zero
View Solution
Solution:
Option (A): When two rows of a matrix are swapped, the determinant of the new matrix is the negative of the determinant of the original matrix. Hence, (A) is correct.
Option (B): Swapping two rows of an invertible matrix does not affect its invertibility because the determinant remains non-zero. Hence, (B) is correct.
Option (C): Swapping rows of a symmetric matrix does not guarantee symmetry, as the symmetry condition A[i][j] = A[j][i] may be violated. Hence, (C) is incorrect.
Option (D): The trace of a matrix is the sum of its diagonal elements, which is independent of row swaps. Hence, if the trace of A is zero, the trace of B remains zero. This makes (D) incorrect.
Question 48:
Let S1 and S2 be two stacks. S1 has a capacity of 4 elements, and S2 has a capacity of 2 elements. S1 already has 4 elements: 100, 200, 300, and 400, whereas S2 is empty, as shown below.
400 (Top) 300 200 Stack S2 100 Stack S1
Only the following three operations are available: PushToS2: Pop the top element from S1 and push it on S2.
PushToS1: Pop the top element from S2 and push it on S1.
GenerateOutput: Pop the top element from S1 and output it to the user.
Note: - The pop operation is not allowed on an empty stack. - The push operation is not allowed on a full stack. Which of the following output sequences can be generated by using the above operations?
Options:
- (A) 100, 200, 400, 300
- (B) 200, 300, 400, 100
- (C) 400, 200, 100, 300
- (D) 300, 200, 400, 100
View Solution
Solution: The available operations allow for flexible reordering of elements in S1 and S2. By analyzing the given sequences:
1. Sequence (A): The sequence 100, 200, 400, 300 cannot be generated because 400 is above 300 in S1, and moving 400 before 300 without outputting 300 is not possible. Hence, (A) is not feasible.
2. Sequence (B): The sequence 200, 300, 400, 100 can be generated as follows: - Use GenerateOutput to output 200 and 300.
- Push 400 to S2 and output 100.
- Retrieve 400 from S2 and output it. Hence, (B) is feasible.
3. Sequence (C): The sequence 400, 200, 100, 300 can be generated by:
- Use GenerateOutput to output 400.
- Push 300 and 200 to S2.
- Output 100 from S1.
- Retrieve 300 from S2 and output it. Hence, (C) is feasible.
4. Sequence (D): The sequence 300, 200, 400, 100 can be generated by:
- Push 400 to S2.
- Use GenerateOutput to output 300 and 200.
- Retrieve 400 from S2 and output it.
- Finally, output 100. Hence, (D) is feasible.
Question 49:
Which of the following is/are EQUAL to 224 in radix-5 (i.e., base-5) notation?
Options:
- (A) 64 in radix-10
- (B) 100 in radix-8
- (C) 50 in radix-16
- (D) 121 in radix-7
View Solution
Solution: The given number 224 in radix-5 can be converted to decimal (radix-10) as follows:
2245 = 2 * 52 + 2 * 51 + 4 * 50 = 50 + 10 + 4 = 64.
Now, check each option:
Option (A): 64 in radix-10 matches the decimal value of 2245. Hence, (A) is correct.
Option (B): Convert 1008 (radix-8) to decimal:
1008 = 1 * 82 + 0 * 81 + 0 * 80 = 64.
This matches 2245. Hence, (B) is correct.
Option (C): Convert 5016 (radix-16) to decimal:
5016 = 5 * 161 + 0 * 160 = 80.
This does not match 2245. Hence, (C) is incorrect.
Option (D): Convert 1217 (radix-7) to decimal:
1217 = 1 * 72 + 2 * 71 + 1 * 70 = 49 + 14 + 1 = 64.
This matches 2245. Hence, (D) is correct.
Question 50:
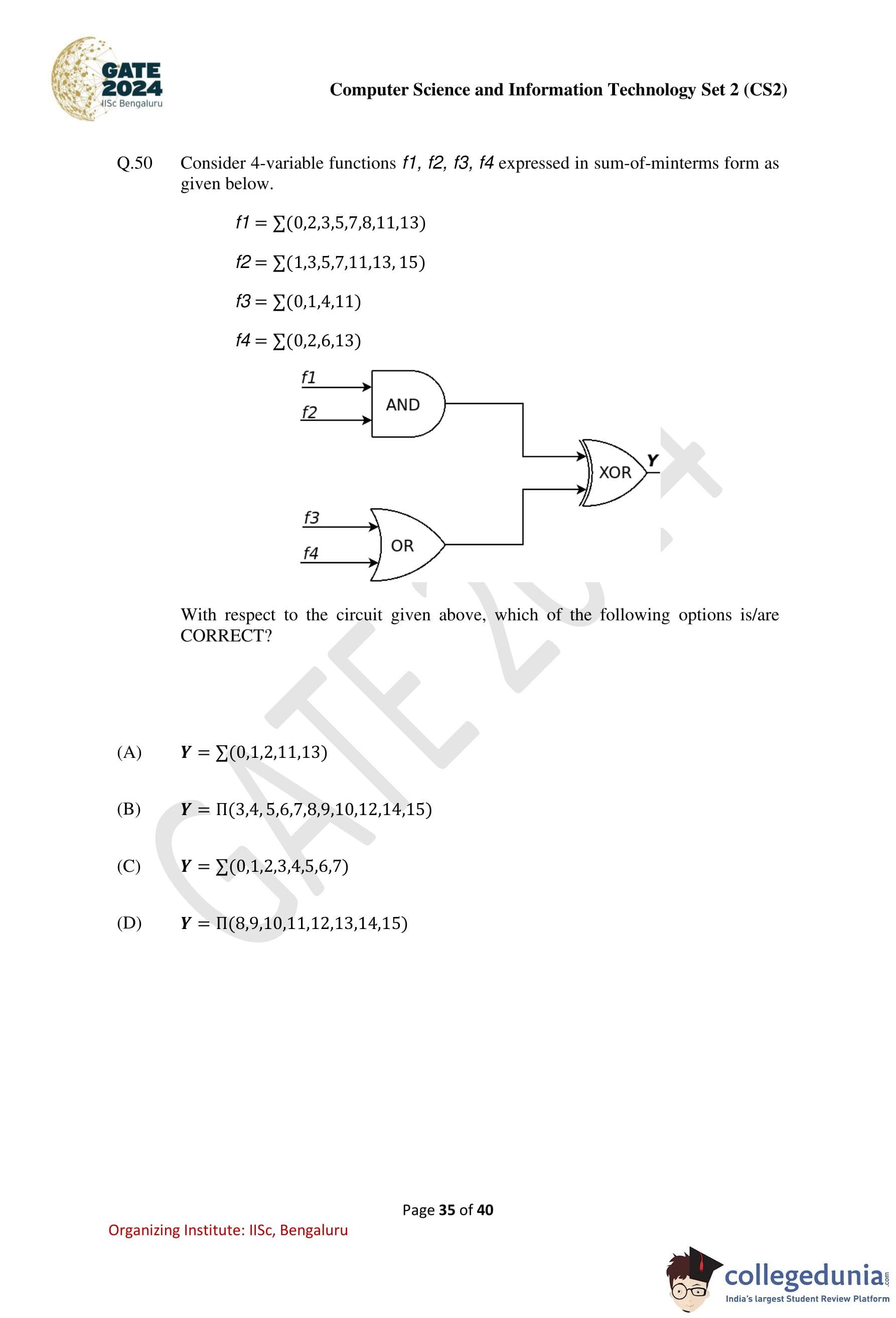
Consider 4-variable functions f1, f2, f3, f4 expressed in sum-of-minterms form as given below. f1 = Σ(0, 2, 3, 5, 7, 8, 11, 13) f2 = Σ(1, 3, 5, 7, 11, 13, 15) f3 = Σ(0, 1, 4, 11) f4 = Σ(0, 2, 6, 13) The circuit is represented as:

With respect to the circuit given above, which of the following options is/are CORRECT?
Options:
- (A) Y = Σ(0, 1, 2, 11, 13)
- (B) Y = Π(3, 4, 5, 6, 7, 8, 9, 10, 12, 14, 15)
- (C) Y = Σ(0, 1, 2, 3, 4, 5, 6, 7)
- (D) Y = Π(8, 9, 10, 11, 12, 13, 14, 15)
View Solution
Question 51:
Let G be an undirected connected graph in which every edge has a positive integer weight. Suppose that every spanning tree in G has even weight. Which of the following statements is/are TRUE for every such graph G?
Options:
- (A) All edges in G have even weight
- (B) All edges in G have even weight OR all edges in G have odd weight
- (C) In each cycle C in G, all edges in C have even weight
- (D) In each cycle C in G, either all edges in C have even weight OR all edges in C have odd weight
View Solution
Solution: If every spanning tree in G has an even weight, it implies a specific structure for the graph G.
Consider the properties:
Option (A): Incorrect. Not all edges in G need to have even weight; some edges can have odd weights as long as the total weight of spanning trees remains even.
Option (B): Incorrect. G may contain both even and odd weighted edges.
Option (C): Incorrect. It is not necessary for all edges in any cycle C to have even weight.
Option (D): Correct. For every cycle C in G, the parity of the edges must be consistent (all even or all odd) to ensure that every spanning tree has an even total weight.
Question 52:
Consider a context-free grammar G with the following 3 rules:
S → aSbS S → aS S → c
Let w ∈ L(G). Let na(w), nb(w), nc(w) denote the number of times a, b, c occur in w, respectively. Which of the following statements is/are TRUE?
Options:
- (A) na(w) > nb(w)
- (B) na(w) > nc(w) - 2
- (C) nc(w) = nb(w) + 1
- (D) nc(w) = nb(w) * 2
View Solution
Solution: The grammar G generates strings of the form: w = ancbn-1, where the derivation of c adds one b and one a. Hence, the relationships between na(w), nb(w), nc(w) can be analyzed:
Option (A): Incorrect. While na(w) is often greater than nb(w), there is no guarantee, as na(w) and nb(w) depend on the specific derivation.
Option (B): Correct. Since the derivation adds at least two a's for every c, the inequality na(w) > nc(w) – 2 holds.
Option (C): Correct. Each derivation of S → aSbS adds one b for every c, making nc(w) = nb(w) + 1.
Option (D): Incorrect. The number of c's is not necessarily twice the number of b's.
Question 53:
Consider a disk with the following specifications: rotation speed of 6000 RPM, average seek time of 5 milliseconds, 500 sectors/track, 512-byte sectors. A file has content stored in 3000 sectors located randomly on the disk. Assuming average rotational latency, the total time (in seconds, rounded off to 2 decimal places) to read the entire file from the disk is ____.
View Solution
Solution: The total time to read the file consists of:
Seek time: Average seek time is 5 ms.
Rotational latency: For a rotation speed of 6000 RPM, the time for one rotation is: Time per rotation = (60 sec) / 6000 = 0.01 sec. The average rotational latency is half the time per rotation: Average rotational latency = 0.01 / 2 = 0.005 sec = 5 ms.
Data transfer time per sector: Each track has 500 sectors. The time to transfer one sector is: Time per sector = (Time per rotation)/(Sectors per track) = 0.01 / 500 = 0.00002 sec = 20 μs.
Total time per sector: Total time to access one sector is: Time per sector = Seek time + Rotational latency + Transfer time. Time per sector = 5 ms + 5 ms + 20 μs = 10.02 ms.
Total time for 3000 sectors: Total time = 3000 × 10.02 ms = 30060 ms = 30.06 sec.
Question 54:
Consider a TCP connection operating at a point of time with the congestion window of size 12 MSS (Maximum Segment Size), when a timeout occurs due to packet loss. Assuming that all the segments transmitted in the next two RTTs (Round Trip Time) are acknowledged correctly, the congestion window size (in MSS) during the third RTT will be ____.
View Solution
Solution: When a timeout occurs, TCP congestion control reduces the congestion window to 1 MSS and enters the slow-start phase. In slow start:
During the first RTT, the window size doubles: 1 → 2MSS.
During the second RTT, the window size doubles again: 2 → 4 MSS.
Thus, at the start of the third RTT, the congestion window size will be 4MSS.
Question 55:
Consider an Ethernet segment with a transmission speed of 108 bits/sec and a maximum segment length of 500 meters. If the speed of propagation of the signal in the medium is 2 × 108 meters/sec, then the minimum frame size (in bits) required for collision detection is ____.
View Solution
Solution: The round-trip time for a signal to propagate across the segment is:
Time = 2 * (Distance / Propagation speed) = 2 * (500 / (2 * 108)) = 5 μs.
To detect collisions, the frame transmission time must be at least equal to the round-trip time. The frame transmission time is: Frame transmission time = Frame size / Transmission speed.
Equating the two: Frame size / 108 = 5 μs => Frame size = 108 × 5 × 10-6 = 500 bits.
Question 56:
A functional dependency F: X → Y is termed as a useful functional dependency if and only if it satisfies all the following three conditions:
- X is not the empty set.
- Y is not the empty set.
- Intersection of X and Y is the empty set.
For a relation R with 4 attributes, the total number of possible useful functional dependencies is ____.
View Solution
Solution: For a relation R with 4 attributes {A, B, C, D}, we need to compute the total number of useful functional dependencies X → Y, where:
• X is a non-empty subset of the attributes.
• Y is a non-empty subset of the attributes.
• X and Y are disjoint (X ∩ Y = Ø).
Step 1: Total number of subsets of R
The total number of subsets of {A, B, C, D} is 24 = 16. These subsets include:
{Ø, {A}, {B}, {C}, {D}, {A, B}, {A, C}, ..., {A, B, C, D}}.
Excluding the empty set, there are 15 non-empty subsets.
Step 2: Counting valid combinations of X and Y
Since X ∩ Y = Ø, Y must be chosen from the attributes that are not in X. For a fixed X:
• The size of X determines the attributes available for Y.
• If X contains k attributes, then 4 - k attributes are available for Y.
For every non-empty subset X (15 options), the number of possible non-empty subsets of the remaining attributes (Y) is: 24-|X| - 1.
Step 3: Summing over all valid combinations
To find the total number of useful functional dependencies, sum over all non-empty subsets X:
Total functional dependencies = ∑k=14 (4Ck) * (24-k - 1), where (4Ck) is the number of ways to choose k attributes for X.
Step 4: Calculate each term for k = 1, 2, 3, 4:
• For k = 1: (4C1) * (24-1 - 1) = 4 * (8 - 1) = 4 * 7 = 28.
• For k = 2: (4C2) * (24-2 - 1) = 6 * (4 - 1) = 6 * 3 = 18.
• For k = 3: (4C3) * (24-3 - 1) = 4 * (2 - 1) = 4 * 1 = 4.
• For k = 4: (4C4) * (24-4 - 1) = 1 * (1 - 1) = 0.
Step 5: Add the results
The total number of useful functional dependencies is: 28 + 18 + 4 + 0 = 50.
Question 57:
A processor with 16 general-purpose registers uses a 32-bit instruction format. The instruction format consists of an opcode field, an addressing mode field, two register operand fields, and a 16-bit scalar field. If 8 addressing modes are to be supported, the maximum number of unique opcodes possible for every addressing mode is ____.
View Solution
Solution: The 32-bit instruction format is divided as follows:
• 16 general-purpose registers: Each register requires 4 bits (24 = 16).
• Two register operand fields: Each operand field is 4 bits, for a total of 8 bits.
• Addressing mode field: 3 bits to represent 8 addressing modes (23 = 8).
• Scalar field: 16 bits.
The remaining bits are allocated to the opcode field: Opcode bits = 32 - (8 + 3 + 16) = 5 bits.
The total number of unique opcodes for every addressing mode is: 2Opcode bits = 25 = 32.
Question 58:
A non-pipelined instruction execution unit operating at 2 GHz takes an average of 6 cycles to execute an instruction of a program P. The unit is then redesigned to operate on a 5-stage pipeline at 2 GHz. Assume that the ideal throughput of the pipelined unit is 1 instruction per cycle. In the execution of program P, 20% instructions incur an average of 2 cycles stall due to data hazards and 20% instructions incur an average of 3 cycles stall due to control hazards. The speedup (rounded off to one decimal place) obtained by the pipelined design over the non-pipelined design is ____.
View Solution
Solution:
Step 1: Define throughput for a pipelined processor. The throughput of a pipelined processor is the number of instructions coming out from the last stage of the pipeline per unit time. In this case, the time unit is 1 clock cycle, which is 0.5 ns. This means that each stage in the pipelined processor takes only 1 clock cycle to operate (ignoring register delay and clock skew).
Step 2: Define CPI for pipelined and non-pipelined processors. The CPI (Clock Cycles Per Instruction) is defined as the average clock cycles per instruction. For a non-pipelined processor, it takes 6 clock cycles to complete an instruction, whereas for a pipelined processor, it takes only 1 clock cycle on average to complete an instruction. Thus: CPI (non-pipelined) = 6, CPI (pipelined) = 1.
Step 3: Define the speedup of the pipelined processor. The speedup of the pipelined processor compared to the non-pipelined processor is given by: Speedup = (CPI (non-pipelined)) / (Ideal CPI (pipelined) + Pipeline stall clock cycles). Here, the pipeline stall clock cycles are added because some clock cycles are wasted due to stalls in the pipeline.
Step 4: Calculate the speedup. For a program with a total instruction count of IC, the pipeline stall clock cycles are due to 20% of the instructions stalling for 2 cycles and another 20% of the instructions stalling for 3 cycles. The effective CPI for the pipelined processor becomes: Effective CPI (pipelined) = 1 + (20% * 2) + (20% * 3). Substitute the values: Effective CPI (pipelined) = 1 + 0.4 + 0.6 = 2. The speedup is then calculated as: Speedup = CPI (non-pipelined) / Effective CPI (pipelined) = 6 / 2 = 3.
Step 5: Conclude the result. The pipelined processor is 3.0 times faster than the non-pipelined processor.
Question 59:
The number of distinct minimum-weight spanning trees of the following graph is ____.

View Solution
Solution:
Step 1: Analyze the graph and find the minimum weight. The graph has 7 edges with weights: 2, 2, 2, 3, 3, 3, 1. To construct a minimum spanning tree (MST), the sum of edge weights must be minimized.
Step 2: Apply Kruskal's algorithm. Using Kruskal's algorithm:
- Select the edge with weight 1 (unique choice).
- Choose three edges of weight 2. These edges form a cycle, allowing multiple choices.
- Choose one edge of weight 3 to complete the MST.
Step 3: Count the distinct combinations.
- There are 3C2 = 3 ways to choose two edges of weight 2.
- For each choice, there are 3 ways to select one edge of weight 3.
The total number of distinct MSTs is: 3 * 3 = 9.
Question 60:
The chromatic number of a graph is the minimum number of colours used in a proper colouring of the graph. The chromatic number of the following graph is ____.

View Solution
Question 61:
A processor uses a 32-bit instruction format and supports byte-addressable memory access. The ISA of the processor has 150 distinct instructions. The instructions are equally divided into two types, namely R-type and I-type, whose formats are shown below.
R-type Instruction Format: OPCODE UNUSED DST Register SRC Register1 SRC Register2 I-type Instruction Format: OPCODE DST Register SRC Register #Immediate Value/Address
In the OPCODE, 1 bit is used to distinguish between I-type and R-type instructions, and the remaining bits indicate the operation. The processor has 50 architectural registers, and all register fields in the instructions are of equal size. Let X be the number of bits used to encode the UNUSED field, Y be the number of bits used to encode the OPCODE field, and Z be the number of bits used to encode the immediate value/address field. The value of X + 2Y + Z is ____.
View Solution
Solution:
Step 1: Instruction format analysis. Each instruction is 32 bits in total. Based on the formats:
• R-type instruction fields:
OPCODE + UNUSED + DST Register + SRC Register1 + SRC Register2 = 32 bits.
• I-type instruction fields:
OPCODE + DST Register + SRC Register + Immediate Value/Address = 32 bits.
Step 2: Determine the number of bits for the registers. The processor has 50 architectural registers. The number of bits required to uniquely identify a register is: Register bits = [log2(50)] = 6 bits. Thus, each register field (DST Register, SRC Register1, SRC Register2) uses 6 bits.
Step 3: Determine the number of bits for the OPCODE field. The ISA contains 150 distinct instructions, equally divided into R-type and I-type. Since 1 bit in the OPCODE field is used to distinguish between instruction types, the remaining bits encode the operations: OPCODE bits = [log2(150)] = 8 bits.
Step 4: Calculate the number of bits for the UNUSED field (R-type) and Immediate Value/Address field (I-type).
• R-type: From the total 32 bits, the UNUSED field is: X = 32 - (OPCODE + 3 × Register bits) = 32 - (8 + 3 * 6) = 6 bits.
• I-type: The Immediate Value/Address field uses: Z = 32 - (OPCODE + 2 × Register bits) = 32 - (8 + 2 * 6) = 12 bits.
Step 5: Compute X + 2Y + Z. Substituting the values of X, Y, and Z: X + 2Y + Z = 6 + 2 * 8 + 12 = 34.
Question 62:
Let L1 be the language represented by the regular expression b*ab*(ab*ab*)* and L2 = {w ∈ (a + b)* | |w| ≤ 4}, where |w| denotes the length of string w. The number of strings in L2 which are also in L1 is ____.
View Solution
Solution:
Step 1: Define the set of language symbols. Let the set of language symbols be: Σ = {a, b} => |Σ| = 2.
Step 2: Define the regular language L1. The regular language L1 is defined as the set of strings where the number of a's is odd.
Step 3: Analyze the strings with an odd number of a's. For all strings with the alphabet set {a,b} of length n, half of them will have an odd number of a's. This can be expressed as: 2n / 2 , where the numerator 2n represents the total number of strings of length n (based on the number of input symbols).
Step 4: Calculate the total number of strings in L1 for all lengths up to 4. We sum up half of the total strings of all lengths (up to 4) in L1: 20 / 2 + 21 / 2 + 22 / 2 + 23 / 2 + 24 / 2
Simplify the terms: 0 + 1 + 2 + 4 + 8 = 15.
The total number of strings in L1 (up to length 4) is 15.
Question 63:
Let Zn be the group of integers {0, 1, 2, . . ., n − 1} with addition modulo n as the group operation. The number of elements in the group Z2 × Z3 × Z4 that are their own inverses is ____.
View Solution
Solution:
Step 1: Define the property of an element being its own inverse. An element x in a group is its own inverse if: x + x = 0 (mod n). This simplifies to: 2x = 0 (mod n).
Step 2: Analyze each group.
• Z2: The elements are {0,1}. 2x = 0 (mod 2) => x = 0,1.
• Z3: The elements are {0, 1, 2}. 2x = 0 (mod 3) => x = 0.
• Z4: The elements are {0, 1, 2, 3}. 2x = 0 (mod 4) => x = 0,2.
Step 3: Combine the results for Z2 × Z3 × Z4. The total number of elements in Z2 × Z3 × Z4 is: |Z2 × Z3 × Z4| = 2 × 3 × 4 = 24. For an element (x2, x3, x4) ∈ Z2 × Z3 × Z4 to be its own inverse:
• x2 ∈ {0,1} (2 choices).
• x3 ∈ {0} (1 choice).
• x4 ∈ {0,2} (2 choices).
The total number of such elements is: 2 * 1 * 2 = 4.
Question 64:
Consider a 32-bit system with a 4 KB page size and page table entries of size 4 bytes each. Assume 1 KB = 210 bytes. The OS uses a 2-level page table for memory management, with the page table containing an outer page directory and an inner page table. The OS allocates a page for the outer page directory upon process creation. The OS uses demand paging when allocating memory for the inner page table, i.e., a page of the inner page table is allocated only if it contains at least one valid page table entry. An active process in this system accesses 2000 unique pages during its execution, and none of the pages are swapped out to disk. After it completes the page accesses, let X denote the minimum and Y denote the maximum number of pages across the two levels of the page table of the process. The value of X + Y is ____.
View Solution
Solution:
Given:
• System address space (VA) = 32 bits.
• Page size (PS) = 4 KB.
• Total pages used by a process (N) = 2000 pages.
• Page table entry size (PTE) = 4 B.
It is given in the question that the OS allocates a page (means single page) for the outer page directory upon process creation.
Step 1: Calculate the total number of bits needed for the outer page table.
The total number of bits needed to represent entries in the outer page table is:
log2(PS / PTE) = log2((212) / (22)) = log2(210) = 10 bits.
Step 2: Calculate the total number of bits needed for the inner page table.
The total number of bits needed to represent entries in the inner page table is: 32 (total VA bits) - 10 (outer PT bits) - 12 (page offset bits) = 10 bits.
Step 3: Calculate X. In each inner page table, we can store 210 entries. The minimum number of page tables (PT) needed to store 2000 pages will be: ⌈2000/210⌉ = 2 PT. Thus: X = 2 + 1 (for the outer PT) = 3.
Step 4: Calculate Y. For occupying the maximum pages in a 2-level page table, we need to place at least one PTE from 2000 pages in every page of the inner page table. This equates to 210 PT. Thus: Y = 210 + 1 (for the outer PT) = 1025.
Step 5: Calculate X + Y. The value of X + Y is: X + Y = 3 + 1025 = 1028.
Question 65:
Consider the following augmented grammar, which is to be parsed with an SLR parser. The set of terminals is {a, b, c, d, #, @}.
S' → S S → SS | Aa | bAc | BC | bAb A → d# B → @
Let I0 = CLOSURE({S' → ·S}). The number of items in the set GOTO(I0, S) is ____.
View Solution
Solution:
Step 1: Analyze the given DFA diagram. The given DFA represents the items in the closure of I0 and the GOTO function for the symbol S.
Step 2: Identify the items in the closure of I0. The closure of I0 contains the following items:
• S' → ·S
• S → ·SS
• S → ·Aa
• S → ·bAc
• S → ·BC
• S → ·bAb
• A → ·d#
• B → ·@
Step 3: Apply the GOTO function on the symbol S. When the GOTO function is applied to S, the following transitions occur:
• S' → S·
• S → S·S
• S → SS·
• S → ·Aa
• S → ·bAc
• S → ·BC
• S → ·bAb
Step 4: Count the total number of items. From the diagram, the GOTO function GOTO(closure(I0), S) results in 9 items: S' → S·, S → S·S, S → SS·, S → Aa·, S → bAc·, S → BC·, S → bAb·, A → d#·, B → @·.
From the above DFA, we can conclude that: GOTO(closure(I0), S) contains 9 items.







































Comments